索引的底层实现原理
索引的底层实现原理
数据库索引是存储在磁盘上的,当数据量大时,就不能把整个索引全部加载到内存了,只能逐一加载每一个磁盘块(对应索引树的节点),索引树越低,越“矮胖”,磁盘IO次数就少
AVL平衡二叉树索引
不管是,增加,删除,还是等值查找,时间复杂度都是O(logn),n 是数据页的数目。并且支持范围查找。
但是当。查找效率低。
数据、索引都是存放在磁盘上,MySQL Server查询数据时需要花费磁盘IO按块读取数据(块一般为16K,内存页面的整数倍)读到内存中
c/c++分配内存:
malloc/new 4字节时,实际上内核的内存管理是按页面(4K)为单位的,如果返回了2个页面,
2 * 4K =8K有8K字节,剩余的字节8k - 4个字节有libc.so或libc++.so库的malloc实现ptmalloc(c库)或者tcmalloc(c++库)来管理
- 缓存,下次再申请内存时直接在ptmalloc或者tcmalloc上申请,不需要访问内核空间
树的层数=log2N=log10N/log102=logN/log2
- 写代码时需要强转换成int类型,否则有小数
for(i=0;i< (int)(log(N)/log(2));i++)- 2000W数据,最坏情况(这些节点都不在一个磁盘块上,一次磁盘IO读取的数据放在一个节点上)下读取一个索引就需要25次磁盘IO
- 若m=500阶的平衡树处理log20000000/log500大约需要3次IO就可以
B树索引
MySQL支持两种索引,一种的B-树索引(但实际上MySQL采用的是B+树结构),一种是哈希索引,大家知道,B-树和哈希表在数据查询时的效率是非常高的。
B-树是一种m阶平衡树,叶子节点都在同一层,由于每一个节点存储的数据量比较大,索引整个B-树的层数是非常低的,基本上不超过三层。
由于磁盘的读取也是按block块操作的(内存是按page页面操作的),因此****,这样一个B-树节点,就可以通过一次磁盘I/O把一个磁盘块的数据全部存储下来,所以当使用B-树存储索引的时候,磁盘I/O的操作次数是最少的()。
MyISAM:
*.MYD *.MYIInnoDB:
*.ibdselect * from student where uid=5;:先检查where过滤字段是否有索引,uid有索引 =》 存储引擎 =》kernel =》 磁盘IO(读索引文件)=》内存上 =》用索引文的数据构建B树,B树的好处是减少磁盘IO加速搜索
没有索引只能做整表搜索,比较慢(一行行的搜索);有索引则加载索引,构建成B树
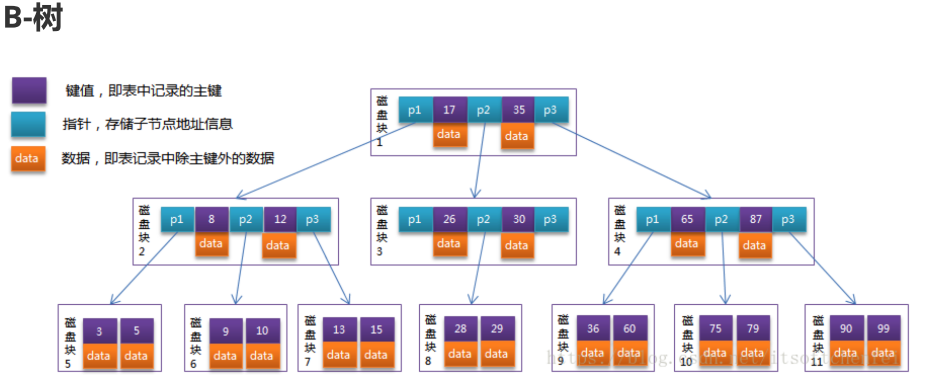
键值就是索引值,比如以name为索引,紫色键值存放的就是name
每个节点的数据都是有序的,因此在一个节点内的搜索是二分搜索log2N O(logN)
单纯看内存上搜索都是O(logN)和AVL树一样,但是好处在于****
**即索引搜索涉及,一个是读取索引文件到内存上构建B树的磁盘IO,另一个就是在内存上B树的搜索是log2N **
- 不是读取全部的索引加载到内存,磁盘读取是按块读取,B-树的节点大小一般设置为和磁盘块大小一致
- 如m=500搜2000W的数据,,内存上搜索25次
data:存储的是数据本身内容?还是磁盘上的地址??
这主要看是什么存储引擎,MyISAM数据和索引分开存储,因此存放的是数据在磁盘上的地址;InnoDB数据和索引存放在同一文件,因此data为数据的内容
B+树
为什么MySQL(MyISAM和InnoDB)索引底层选择B+树而不是B树呢???
B树****
B树的 索引+数据内容 分散在不同的节点上,离根节点近,搜索就快;离根节点远,搜索就慢! 因此,花费的,每一次数据花费的时间也不平均
每一个非叶子节点上,不仅要存储 索引(key),还要存储索引值所在的哪一行的data的数据。因此一个节点,比只存放key值的节点要得多!
B树不方便做看起来也不方便
由上面的三个原因,因此选B+树来构建索引
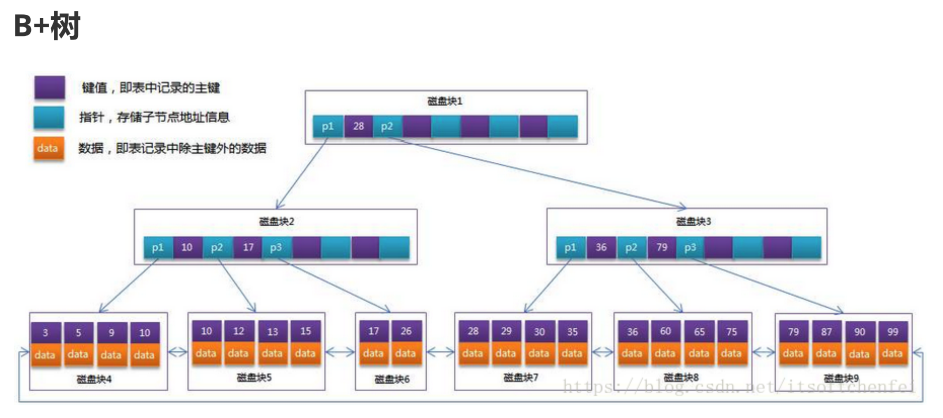
- 每一个非叶子节点只存放key,不存储data!
- 每一个节点存放的key值更多,因此B+树理论上来说,一些,搜索的效率会更好一些
- 叶子节点上存储了所有的索引值以及对应的data
- 搜索每一个索引对应的值data,都需要跑到叶子节点,这样每一行记录搜索的
- 叶子节点被串在一个链表当中,形成了一个有序的链表
- 如果要进行索引树的搜素或者整表搜索,直接即可!!
- 做范围查询的时候,直接遍历叶子节点的有序链表即可!!
:先检查where过滤字段是否有索引,没有索引就做整表搜索,效率比较低;如果有索引,操作系统内核kernel花费磁盘IO,读索引文件到内存上 ,用索引文的数据构建B+树,因为B+树是平衡树,搜索效率比较高;而且是一个节点一个节点构建,一个节点对应一个磁盘IO,非叶子叶节点只存储key,单个节点存储的key值比较多,所有的key和data都是存在叶子节点,
总结回答为什么使用B+树构建索引?
- B-树的每一个节点,存了关键字和对应的数据地址,而B+树的非叶子节点只存关键字,不存数据地址。因此B+树的每一个非叶子节点存储的关键字是远远多于B-树的,B+树的叶子节点存放关键字和数据,因此,从树的高度上来说,B+树的高度要小于B-树,使用的磁盘I/O次数少,因此查询会更快一些。
- B-树由于每个节点都存储关键字和数据,因此离根节点进的数据,查询的就快,离根节点远的数据,查询的就慢;B+树所有的数据都存在叶子节点上,因此在B+树上搜索关键字,找到对应数据的时间是比较平均的,没有快慢之分。
- 在B-树上如果做区间查找,遍历的节点是非常多的;B+树所有叶子节点被连接成了有序链表结构,因此做整表遍历和区间查找是非常容易的。