索引的使用和分析
大约 5 分钟
索引的使用和分析
索引的创建和删除
创建表的时候指定索引字段,会自动给 primary key 和 unique 创建索引。
CREATE TABLE index1(id INT,
name VARCHAR(20),
sex ENUM('male', 'female'),
INDEX (id)); #普通索引,单列索引
CREATE TABLE index1(id INT,
name VARCHAR(20),
sex ENUM('male', 'female'),
INDEX(id, name));#普通索引,多列索引
CREATE TABLE index1(id INT,
name VARCHAR(20),
sex ENUM('male', 'female'),
INDEX(id, name),
INDEX(sex));#创建多个索引
CREATE TABLE index1(id INT,
name VARCHAR(20),
sex ENUM('male', 'female'),
INDEX 'index_name' (id)); #还可以自定义一个索引名
- 查看默认的索引名-
show create table 表名
在已经创建的表上添加索引:
CREATE [UNIQUE] INDEX 索引名 ON 表名(属性名(length) [ASC | DESC]);
- 常针对字符串类型的数据的索引优化,
lenght指定前多少个字符建立索引,只要能区分开就行
create index nameidx on student(name);
删除索引:
DROP INDEX 索引名 ON 表名;
索引的优化
面试回答问题,结合实践,不要背课文1... 2... 3...
经常作为where条件过滤的字段考虑添加索引
字符串列创建索引时,尽量规定索引的长度,而不能让索引值的长度key_len过长
索引字段涉及类型强转、mysql函数调用、表达式计算等,索引就用不上了
MySQL端口号的查看
#查看MySQL的端口号
sudo netstat -tanp|grep mysqld

索引的执行过程
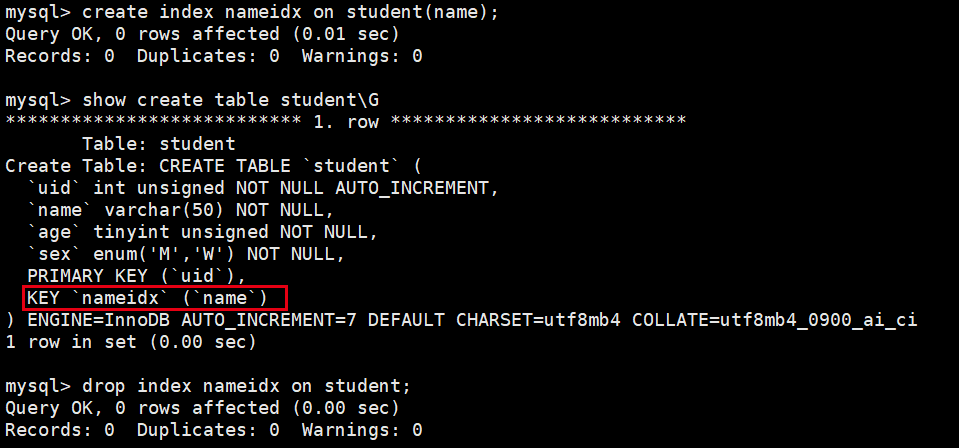
- 需要注意的是,给该字段加了索引并且以该字段作为过滤条件就能用到该索引,因为mysql server有自己的优化,如果使用索引最后得到的数据占总数据的70-81%左右,便不会使用索引
- 使用索引会读取索引文件-花费磁盘IO,如果数据取不完还要去数据表去取数据
- 即,先进行比较,如果使用索引得到的数据量和扫表得到的数据量接近,就不会使用索引,因为使用索引的步骤比较繁琐
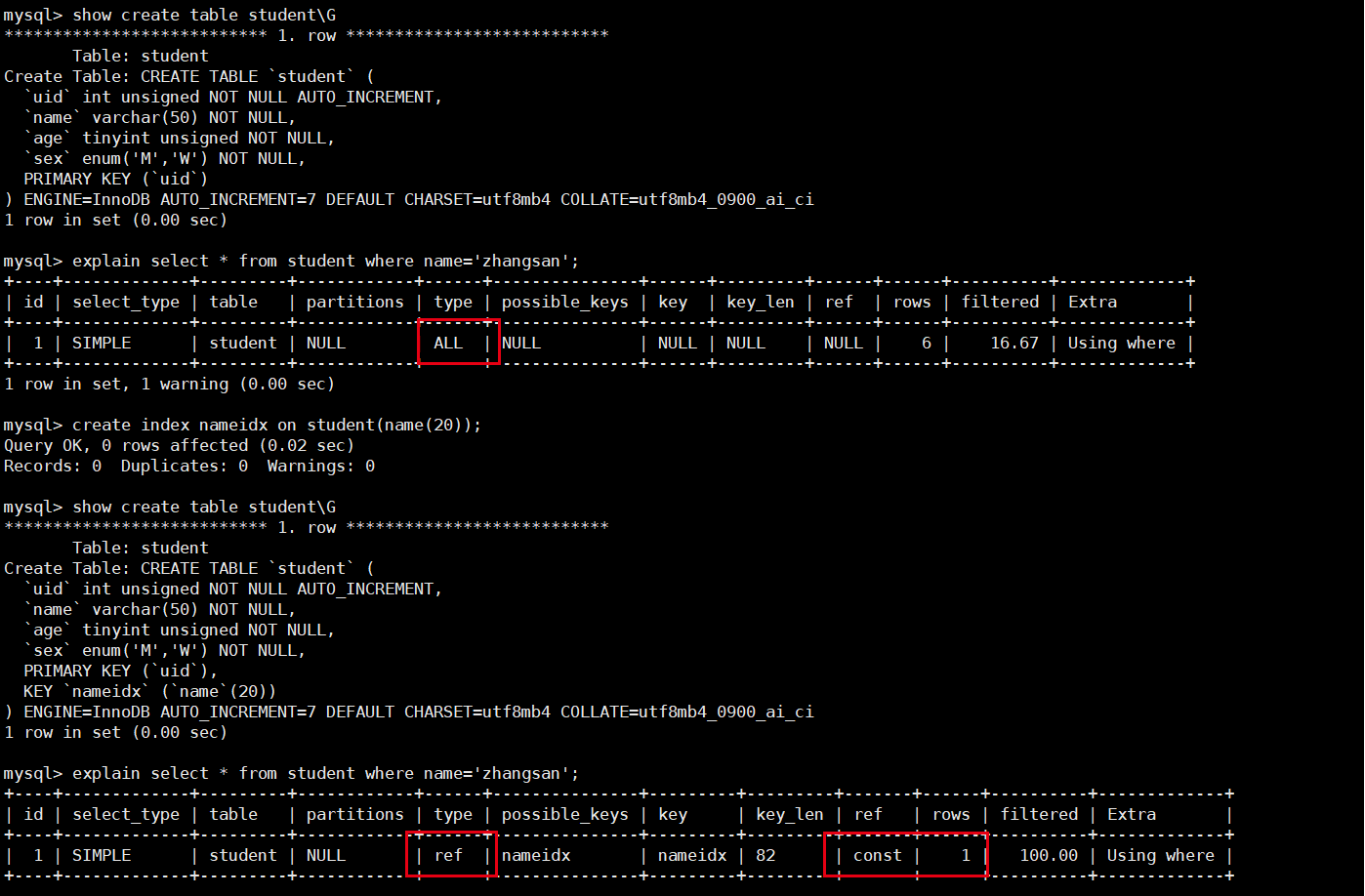
- 索引的好处是,无论数据的位置在哪里,都是常量级的时间
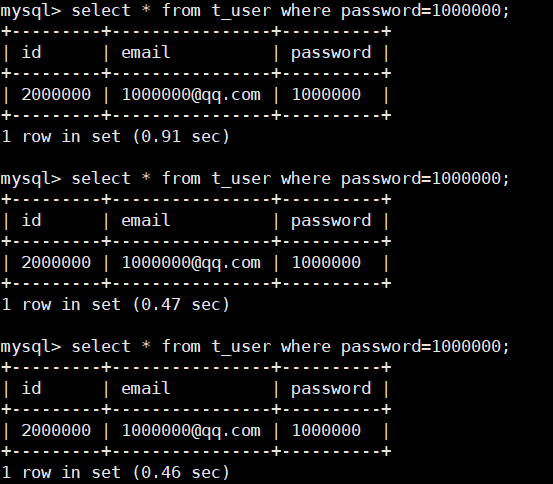
- 第二次速度快是因为有数据缓存和索引缓冲
- 即使有缓存,对于2000000的数据查询时间仍然很长,可以加索引
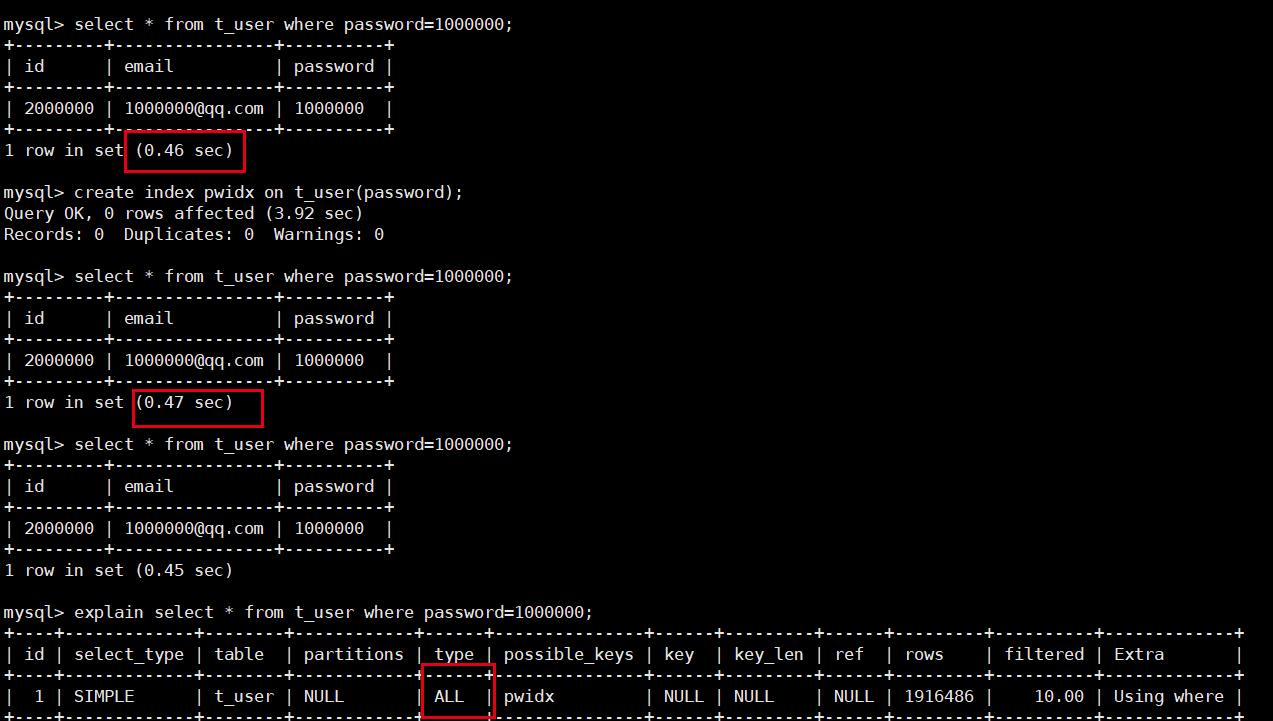
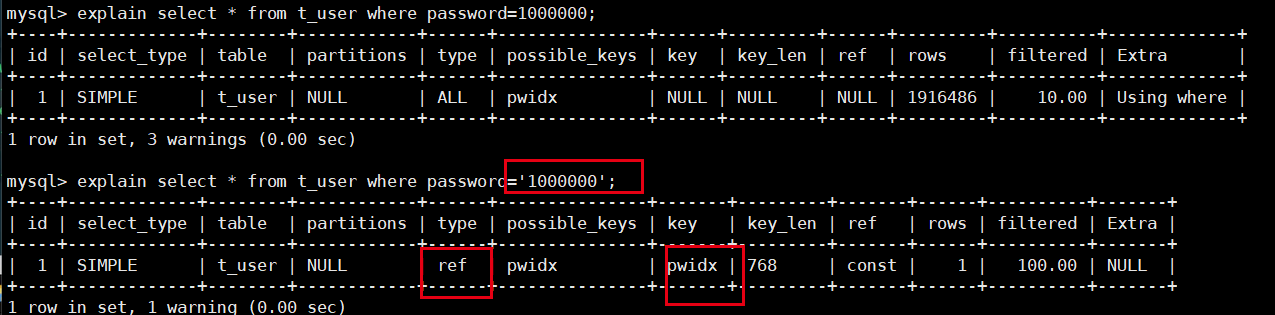
- 由于password设置的是字符串类型,而我们输入
where password=1000000中password是整型,会涉及到类型转换
explain结果字段分析
select_type
- simple:表示不需要union操作或者不包含子查询的简单select语句。有连接查询时,外层的查询为simple且只有一个。
- primary:一个需要union操作或者含有子查询的select,位于最外层的单位查询的select_type即为primary且只有一个。
- union:union连接的两个select查询,除了第一个表外,第二个以后的表的select_type都是 union。
- union result:包含union的结果集,在union和union all语句中,因为它不需要参与查询,所以id字段为null。
table
显示查询的表名;
如果不涉及对数据库操作,这里显示null;
如果显示为尖括号就表示这是个临时表,后边的N就是执行计划中的id,表示结果来自于这个查询产生的;
如果是尖括号括起来<union M,N>也是一个临时表,表示这个结果来自于union查询的id为M,N的结果集;
type
const:使用唯一索引或者主键,返回记录一定是1行记录的等值where条件时,通常type就是const。
ref:常见于辅助索引的等值查找,或者多列主键、唯一索引中,使用第一个列之外的列作为等值查找会出现;返回数据不唯一的等值查找也会出现。
range:索引范围扫描,常见于使用<、>、is null、between、in、like等运算符的查询中。
index:索引全表扫描,把索引从头到尾扫一遍;常见于使用索引列就可以处理不需要读取数据文件的查询,可以使用索引排序或者分组的查询。
all:全表扫描数据文件,然后在server层进行过滤返回符合要求的记录。
ref
如果使用常数等值查询,这里显示const;
如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段;
Extra
- using filesort:排序时无法用到索引,常见于order by和group by语句中。
- using index:查询时不需要回表查询,直接通过索引就可以获取查询的数据。