哈希索引
大约 4 分钟
哈希索引
查看索引类型
show indexes from student;
注意MySQL5.7 show create table 反应的索引类型不准
create index nameidx on student(name) using hash;
show create table student\G
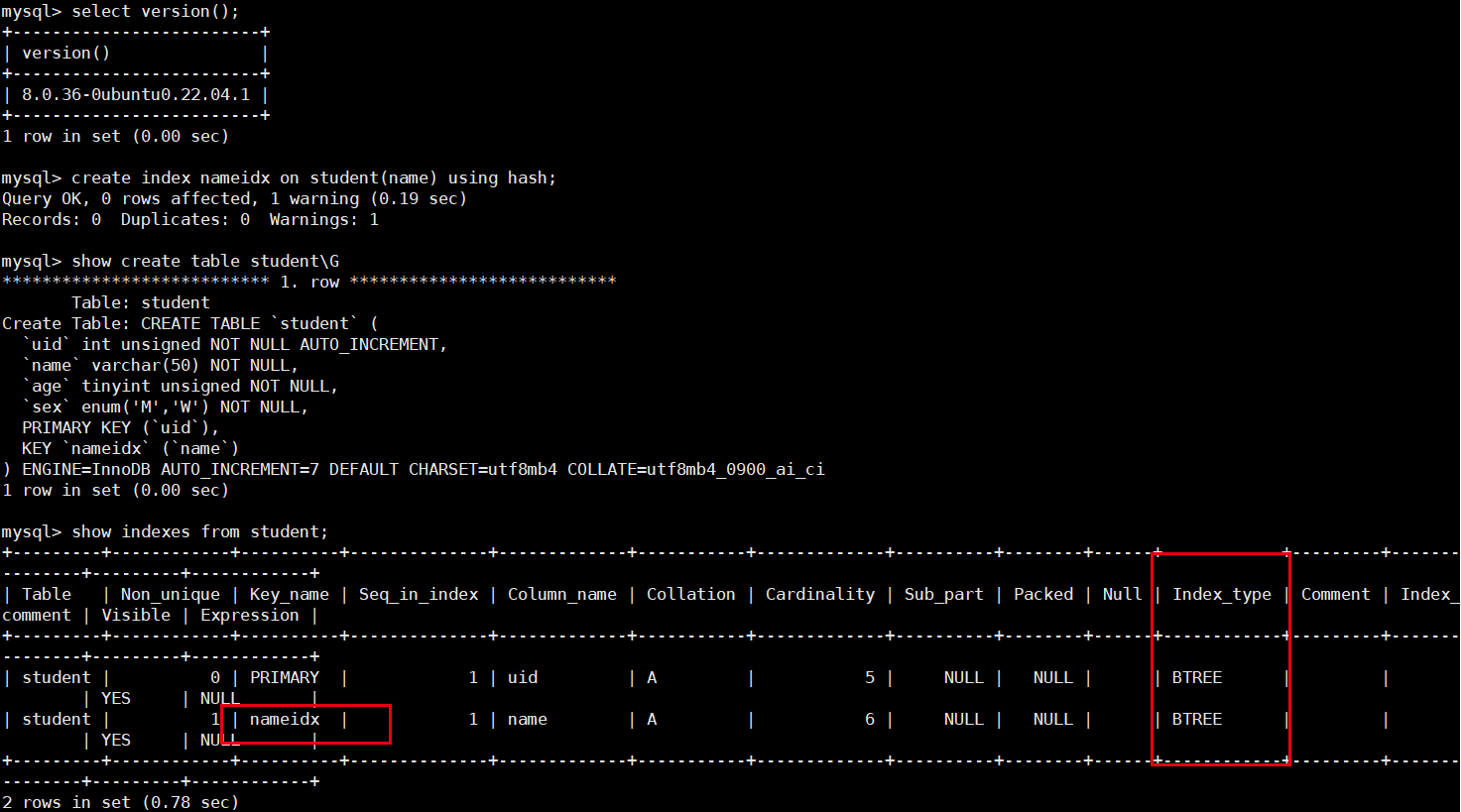
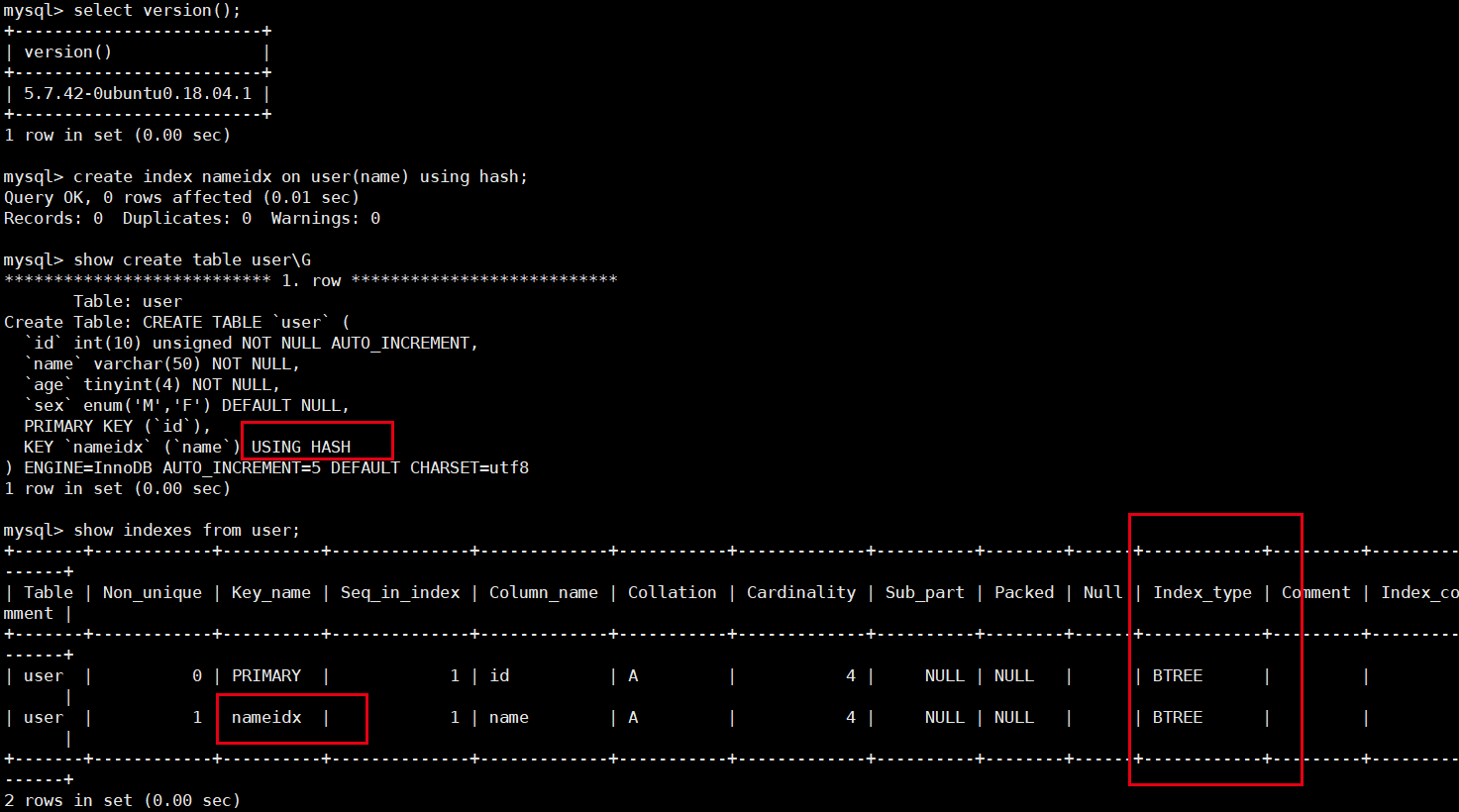
- MySQL5.7 show create 只是显示我们创建索引的时候加的标志,实际上底层到底是不是哈希索引是不准确的
- 因为搜索引擎是InnoDB,默认创建的是B+树
哈希索引
哈希索引是基于的支持,底层结构就是,增删改查的时间复杂度都是,一断电或重启mysql服务器就没了,因为内存搜索,哈希表是最快的
而平衡树的增删改查的时间复杂度是O ( logn ),此外B+树索引是把磁盘上的存储的索引文件加载到内存上构建的数据结构。
看起来哈希表比B+树好,那为什么MyISAM和InnoDB存储引擎用的是B+树索引?
选择哪种数据结构构建索引,我们主要看:
- 搜索的效率要高
- 磁盘IO花费要少
创建哈希索引
如果这个文件使用的是memory基于内存的存储引擎,然后我们创建的索引就是哈希索引,底层是通过链式哈希表实现的
create index nameidx on student(name);
构建链式哈希表:根据选定的哈希函数,把每一行记录的name字段作为参数来求一个哈希值,哈希值对桶的长度取模得到桶的序号(会产生哈希冲突),然后进行存储。
解决哈希冲突的方式:在桶里面用链表串起来(链地址法)
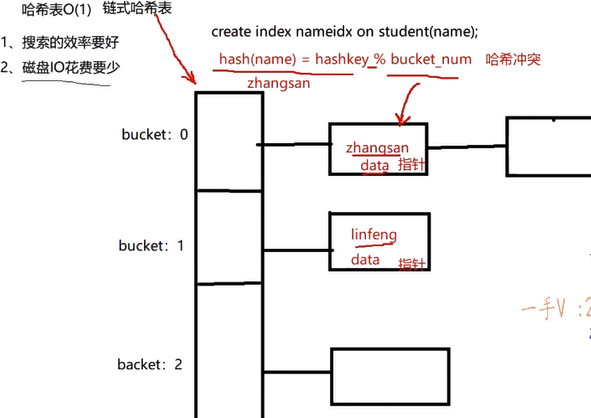
- 注意:,数据在内存的其他位置
注意:虽然链式哈希表的桶看起来有顺序,实际上存储的。因为我们用哈希函数进行了计算,然后还进行了取模的操作,不可能说我输入的索引值的字典序小,就一定在小的桶里面
哈希表只能进行等值查找,比如:
select * from student name="zhangsan";
不能进行,比如:
select * from student name like "zhang%";
- B+输入读取一个块(16K)可以放到相邻的4个页面上;而在哈希表中,不同元素,哪怕是15和16,通过求哈希值,模上桶的个数,最后存储的位置可能会相隔很远。如果用链式哈希表构建索引,一个桶里面的节点代表1次磁盘I/O,由于桶内元素也是没有顺序的,我们进行查找的时候都会遍历完所有的桶内节点,就会导致更多的磁盘I/O。
哈希索引只适用于小数据量的,在内存上的等值查询,处理不在磁盘的数据,并不能为我们减少磁盘I/O的次数!!!
小结
由于不同的索引值经过哈希函数计算以及取模后,最后存储的位置非常不确定,没有任何的顺序,只能进行等值查找,不能进行
由于我们绝大部分的数据都是存放在磁盘的,哈希索引没办法减少磁盘I/O的次数,从磁盘上加载数据到内存的次数太多,使用的比较少
此外一旦哈希表扩容,就会导致所有的索引值重新计算存储位置,效率很低。因此一般数据量也不是很大