单表select查询
select查询
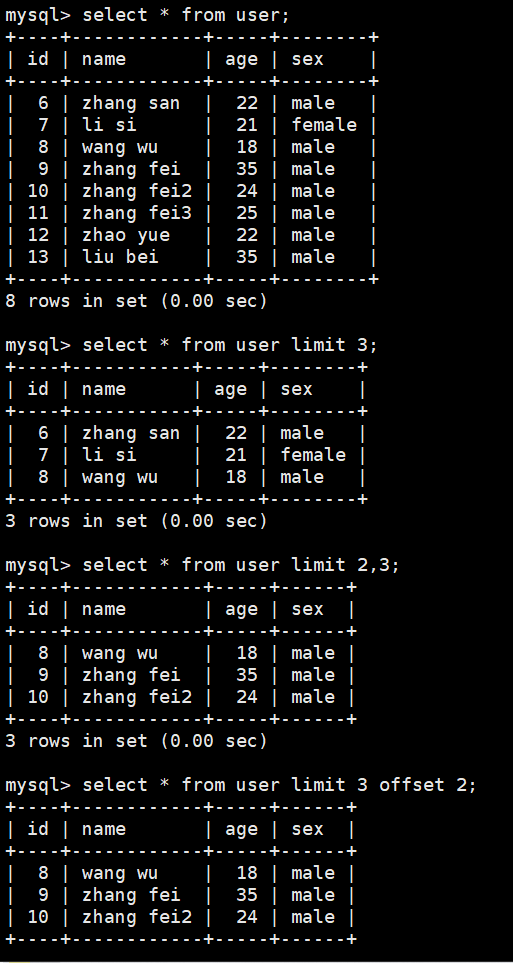
select * from user;
项目中很少使用
select * from user;,而是()- 因为可能后期表结构会根据需求调整,可能会出现没有预料的列出现
- 一下就查询到客户的所有信息,容易造成信息泄露,而第二种方法虽然麻烦点,但是安全程度更高
select name,age,sex from user;select后面选择的具体的列需要具体考虑,因为会涉及****问题,回表会降低查询效率
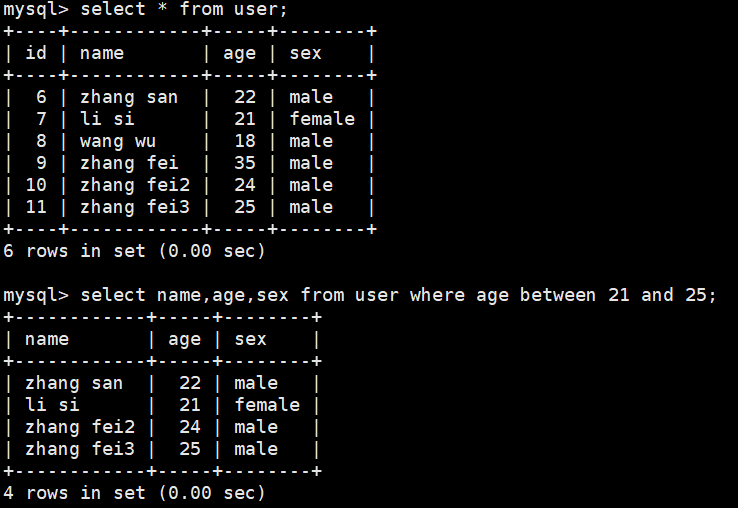
select name from user where age>21 and sex='male';
select name,age,sex from user where age>=21 and age<=25;
select name,age,sex from user where age between 21 and 25;
select name,age,sex from user where name like 'zhang%';
select name,age,sex from user where name like 'zhang_';
select name,age,sex from user where name like '%si%';
去重distinct
查看哪个年龄段有分布-
select distinct age from user;
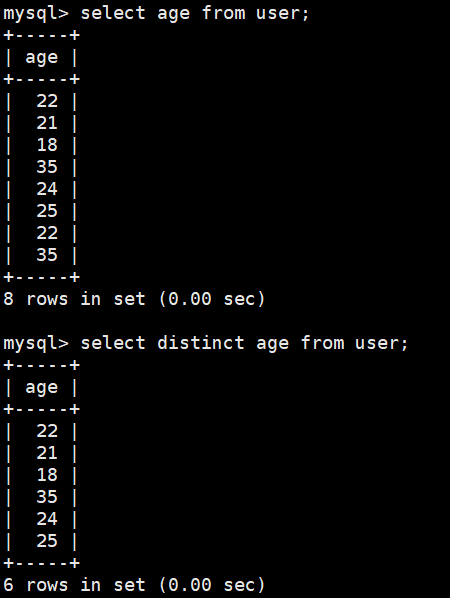
虽然group by也能去重,但是group by功能强大也耗时,可以使用distinct
空值查询
select name,age,sex from user where name is null;
select name,age,sex from user where name is not null;
union 查询
UNION [ALL | DISTINCT] # 注意:union默认去重,不用修饰distinct,
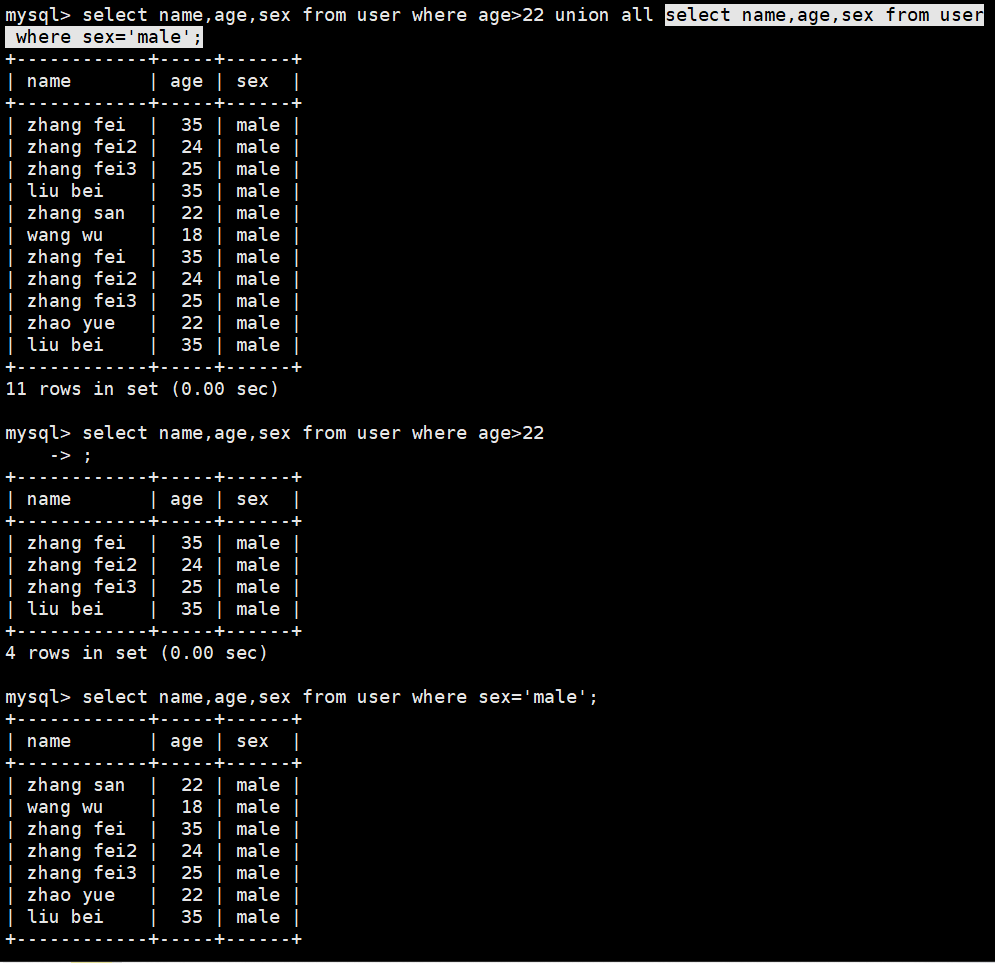
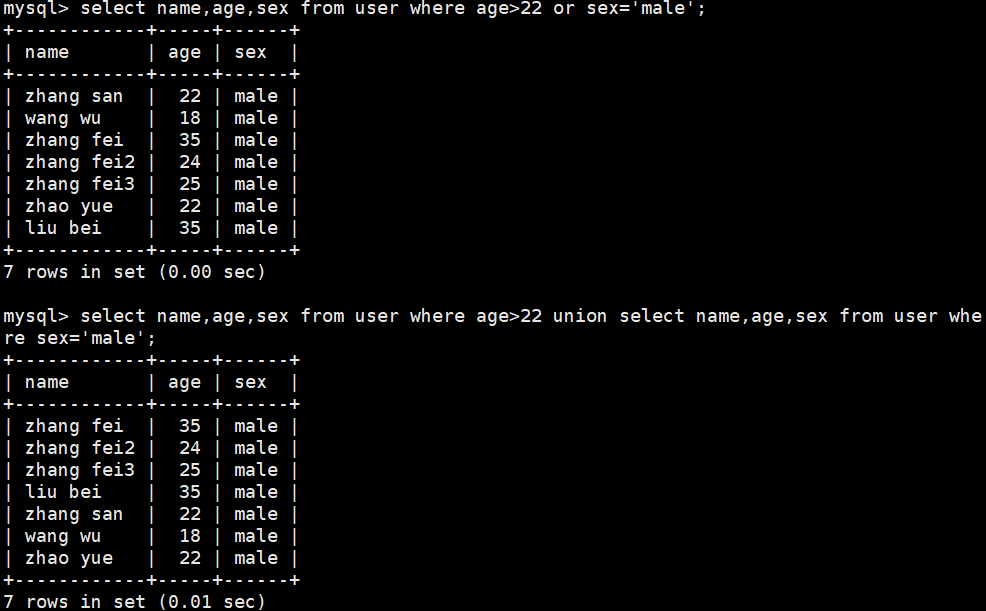
select name,age,sex from user where age>22 or sex='male';
select name,age,sex from user where age>22 union all select name,age,sex from user where sex='male';
仅看====
带in子查询
select name,age,sex from user where age in (20,21);
select name,age,sex from user where age not in (20,21);
select name,age,sex from user where id in(select id from user where age>21);
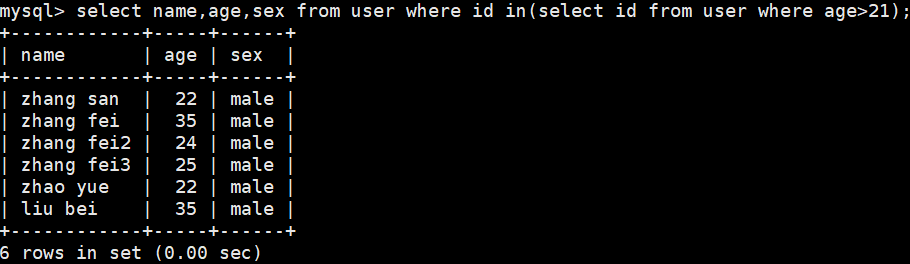
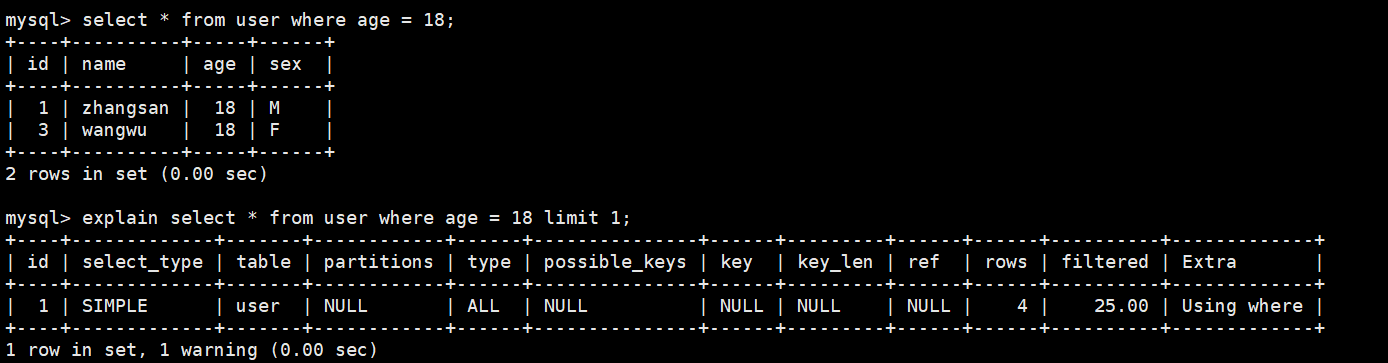
分页查询limit

select * from user limit 3; #limit 0,3
select * from user limit 2,3;
select * from user limit 3 offset 2; #为了兼容其他关系型数据库的分页语法
limit只是对select显示条数进行限制了,还是说还能影响SQL的查询效率呢?
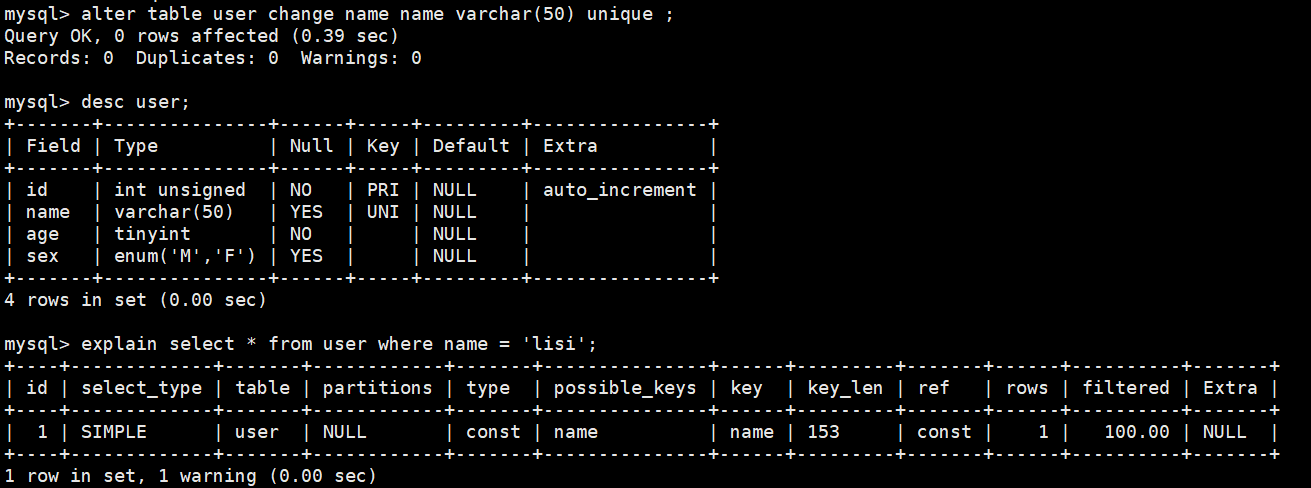
mysql是如何查询的
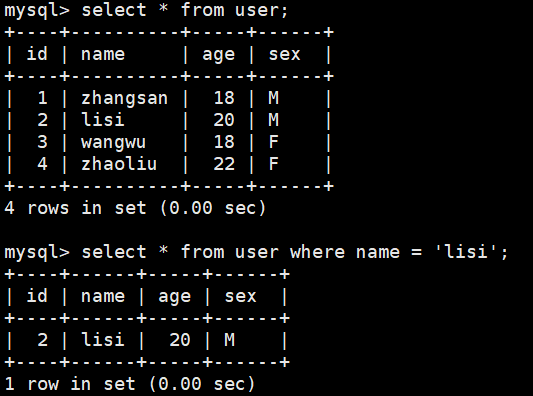
mysql是查找名字为“lisi”的记录,是只找前两行还是全部查找后返回第二行???
如何提高查询效率?
关系型数据库就是二维表,效率的高低取决于扫描表的数据量 ,扫的少效率就高,扫地多效率就低
explain查看执行计划
explain可以将执行语句的执行过程和一些关键信息罗列出来
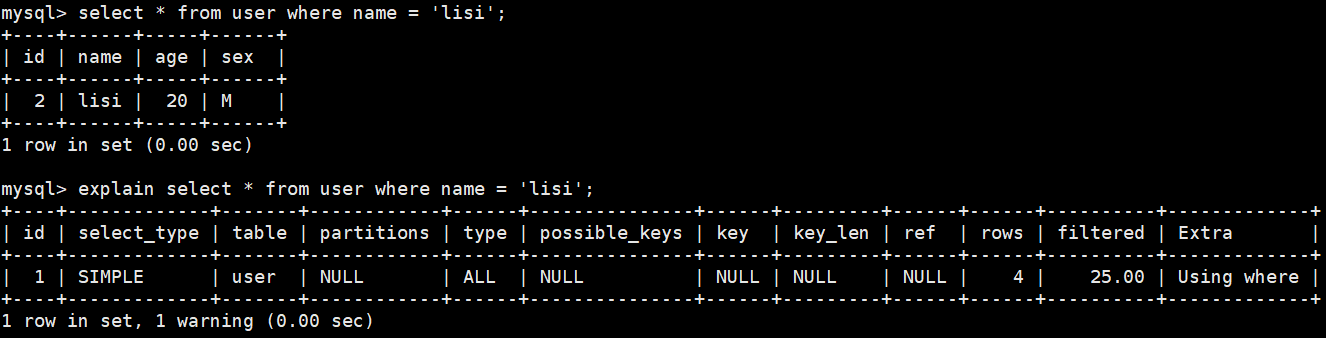
explain各个字段代表的意思
id:select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序- 例子中属于单表搜索,没有联合搜索和多表的查询,因此只有1行
select_type:查询类型 或者是 其他操作类型SIMPLE简单查询,不包括子查询和union查询
table:正在访问哪个表partitions:匹配的分区type:访问的类型NULL > system > const > eq_ref > ref > ref_or_null > index_merge > range > index > ALL- 索引查询是const常量级的时间,表示不管哪个位置查询效率/时间是一样的
possible_keys:显示可能应用在这张表中的索引,一个或多个,但不一定实际使用到key:实际使用到的索引,如果为NULL,则没有使用索引- 如果字段类型是unique,会自动创建一个唯一键索引
key_len:表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度ref:显示索引的哪一列被使用了,如果可能的话,是一个常数,哪些列或常量被用于查找索引列上的值rows:表示查询时扫描的行数- 没有加索引就会全文扫描
- 是索引,只扫1行
filtered:查询的表行占表的百分比Extra:包含不适合在其它列中显示但十分重要的额外信息

limit对于查询的作用
虽然explain查看执行计划显示全文扫描,实际上mysql看到用户只需要1条数据,查询到就会截至查询并返回;
快速插入海量数据-存储过程
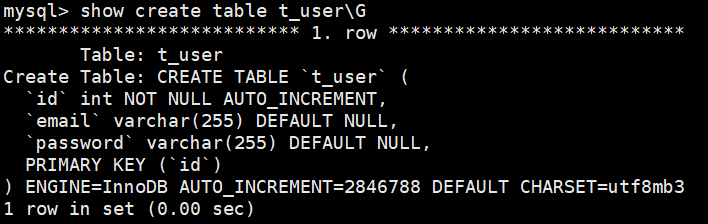
delimiter $ #修改语句结束的符号 ; -> $
Create Procedure add_t_user (IN n INT) #add_t_user 函数名字;n为int型输入变量, out可以定义输出变量
BEGIN
DECLARE i INT; #声明变量, 赋初值也可以这样写declare i int default 0
SET i=0; #如果不修改语句结束符这里分号;代表着语句的结束
WHILE i<n DO #循环条件i<n 循环开始DO
INSERT INTO t_user VALUES(NULL,CONCAT(i+1,'@fixbug.com'),i+1);
SET i=i+1;
END WHILE; #开始循环不加分号,结束循环需要加
END$ #函数结束
delimiter ; #修改回来
call add_t_user(2000000); #调用
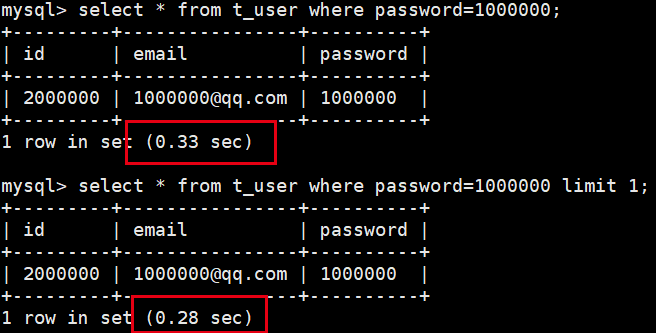
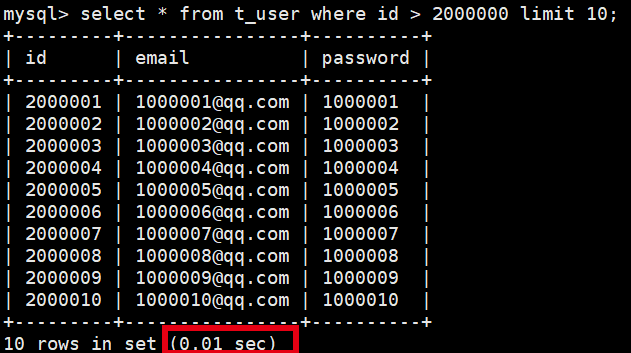
limit实际应用的优化

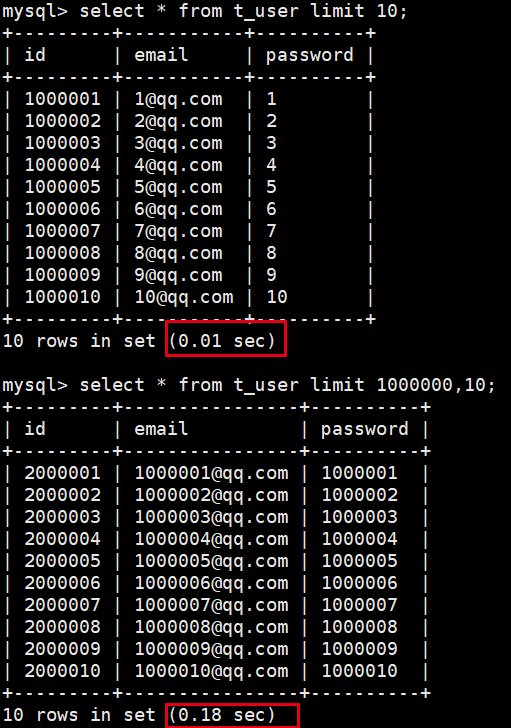
分页查询中,上,因此****
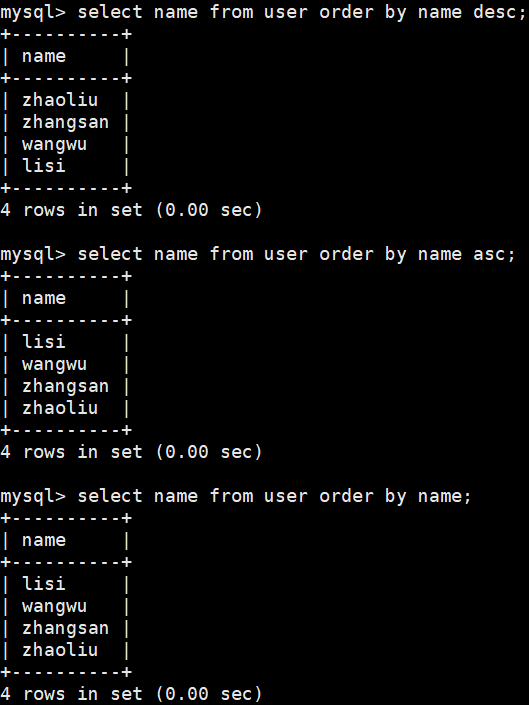
排序order by
select id,nickname,name,age,sex from user where sex='M' and age>=20 and age<=25 order by age asc; #以age升序,不写默认也是升序
select id,nickname,name,age,sex from user where sex='M' and age>=20 and age<=25 order by age desc; #以age降序
select id,nickname,name,age,sex from user where sex='M' and age>=20 and age<=25 order by age,name asc; #总体以age升序,当age相同时再以name升序

当数据量比较大时order by可能会出现比较耗时情况,然后通过explain查看执行计划,发现这条语句涉及到了外排序
- 外排序涉及到了磁盘IO,所以慢
- 如果数据量太大,无法一次性弄到内存中怎么办呢?这种情况下的排序称为外排序。外排序——归并思想的实现_外排序归并问题的算法思想-CSDN博客
优化:
- order by后以索引进行排序
- 注意select后的字段是否涉及到了回表查询
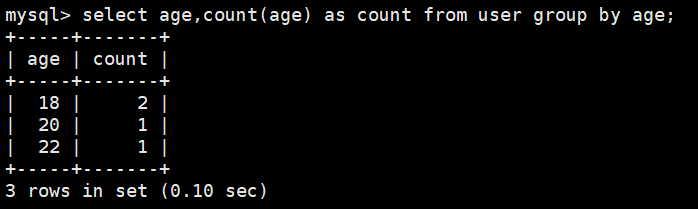
分组group by
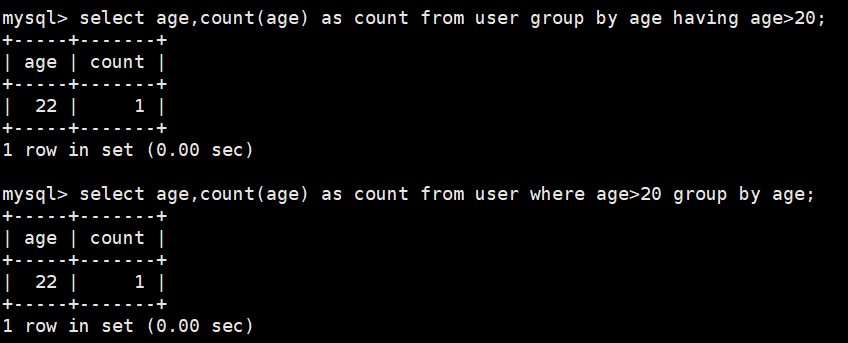
select age,count(age) as count from user group by age;
select age,count(age) as count from user group by age having age>20; #可以使用having对order by结果进行过滤
select age,count(age) as count from user where age>20 group by age;
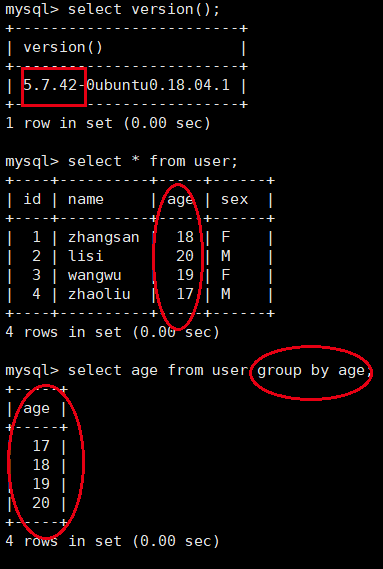
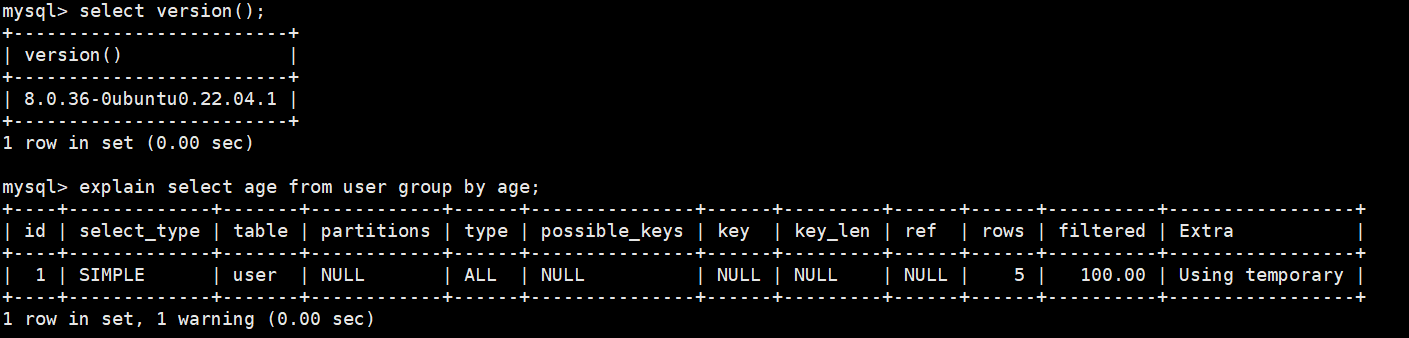
MySQL5.7 group by会自动排序,MySQL8.0没有
MySQL5.7
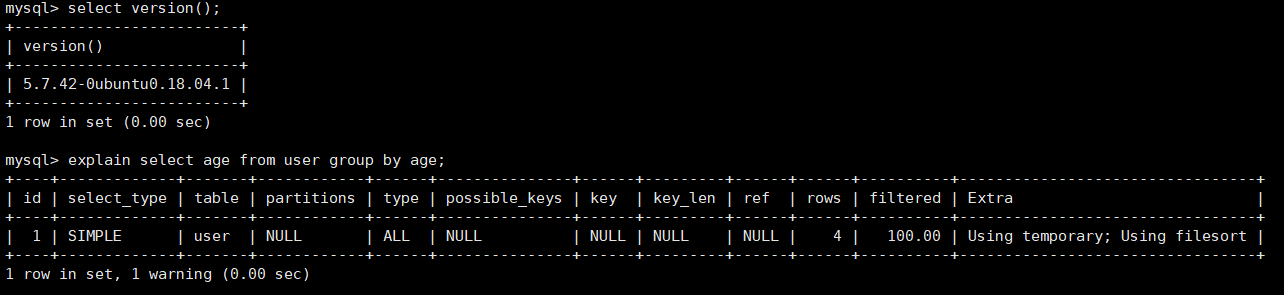
- MySQL5.7分析explain可以看到涉及到了外排序
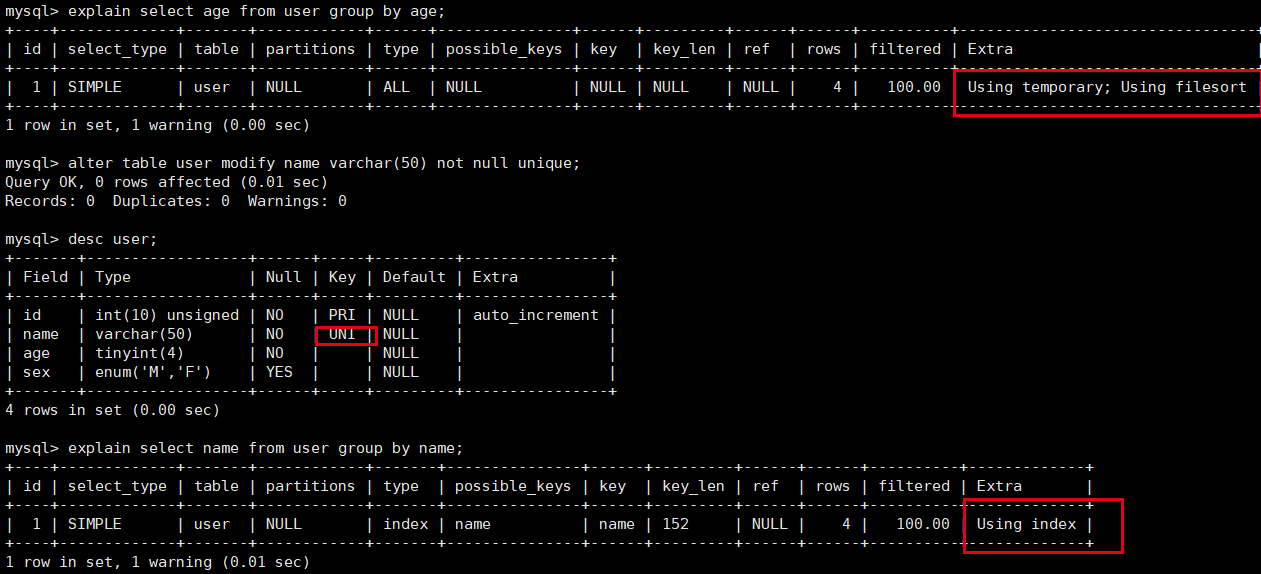
MySQL8.0
注意
order by和group by性能都和索引相关
练习题
下表bank_bill是某银行代缴话费的主流水表结构:
| 字段名 | 描述 |
|---|---|
| serno | 流水号 |
| date | 交易日期 |
| accno | 账号 |
| name | 姓名 |
| amount | 金额 |
| brno | 缴费网点 |
1、统计表中缴费的总笔数和总金额
select count(serno),sum(amount) from bank_bill;
2、给出一个sql,按网点和日期统计每个网点每天的营业额,并按照营业额进行倒序排序
select brno,date,sum(amount) as money from bank_bill group by brno,date order by brno,mone desc;