多表select-连接查询
大约 7 分钟
多表select-连接查询
为什么需要连接查询
当单表设计不满足范式设计时需要进行拆分,因此可能涉及到多表查询。连接查询相比单表查询减少了TCP三次握手和四次挥手,也减少了mysql server对client sql的校验过程。当然,一般满足范式三即可,范式越高表越多,连接查询效率越低。

概述
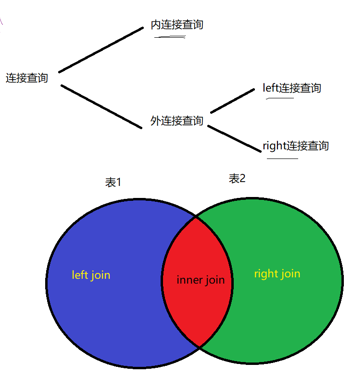
左连接:指的是表1特有的数据
内连接:指的是两个表的交集
右连接:指的是表2特有的数据
内连接
#学生表
CREATE TABLE student(
uid INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50) NOT NULL,
age TINYINT UNSIGNED NOT NULL,
sex ENUM('M', 'W') NOT NULL);
#课程表
CREATE TABLE course(
cid INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
cname VARCHAR(50) NOT NULL COMMENT '课程名称',
credit TINYINT UNSIGNED NOT NULL COMMENT '学分');
#考试结果
CREATE TABLE exame(
uid INT UNSIGNED NOT NULL,
cid INT UNSIGNED NOT NULL,
#time INT UNSIGNED NOT NULL, #int用时间戳表示考试时间 没有用date类型
time DATE NOT NULL, #DATE 年-月-日 比较明显
score FLOAT NOT NULL,
PRIMARY KEY(uid,cid) #一个学生有多门课,一个课又有多个学生,但是这两个组合在一起就是唯一的,使用联合主键
);
insert into student (name, age,sex) values
('zhangsan', 18, 'M'),
('gaoyang', 20, 'W'),
('chenwei', 22, 'M'),
('linfeng', 21, 'W'),
('liuxiang', 19, 'W');
insert into course(cname,credit) values
('C++基础课程',5),
('C++高级课程',10),
('C++项目开发',8),
('C++算法课程',12);
insert into exame (uid,cid, time,score) values
(1,1,'2021-04-09', 99.0),
(1,2,'2021-04-10', 80.0),
(2,2,'2021-04-10', 90.0),
(2,3,'2021-04-12', 85.0),
(3,1,'2021-04-09', 56.0),
(3,2,'2021-04-10', 93.0),
(3,3, '2021-04-12', 89.0),
(3,4, '2021-04-11', 100.0),
(4,4,'2021-04-11', 99.0),
(5,2,'2021-04-10', 59.0),
(5,3,'2021-04-12', 94.0),
(5,4,'2021-04-11', 95.0);
#单表查询
select a.uid,a.name,a.age,a.sex from student as a where a.uid=1;
select c.score from exame c where c.uid=1 and c.cid=2;
#两张表的连接查询
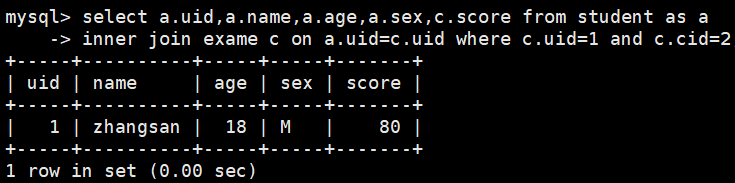
select a.uid,a.name,a.age,a.sex,c.score from student as a
inner join exame c on a.uid=c.uid where c.uid=1 and c.cid=2;
- 别名as,可以省略
- 内连接inner join 或者 join,inner也可以省略
- on 表示按什么连接
- 连接语句中会先以数据量区分大表和小表,小表永远是整表扫描,然后去大表搜索
- 数据量,是满足where过滤后每个表剩余的数据的量(有可能a原本有20行,b有10行,满足where过滤后a还有5行,b不变,那么a为小表,b为大表)
- 因为小表永远整表扫描,有没有索引没意义
- 索引是否用到和select没有关系,要看where过滤时有没有用到
- 即,从student表中取出所有的a.uid,然后拿着这些uid去exame大表中搜索
- 连接语句中会先以数据量区分大表和小表,小表永远是整表扫描,然后去大表搜索
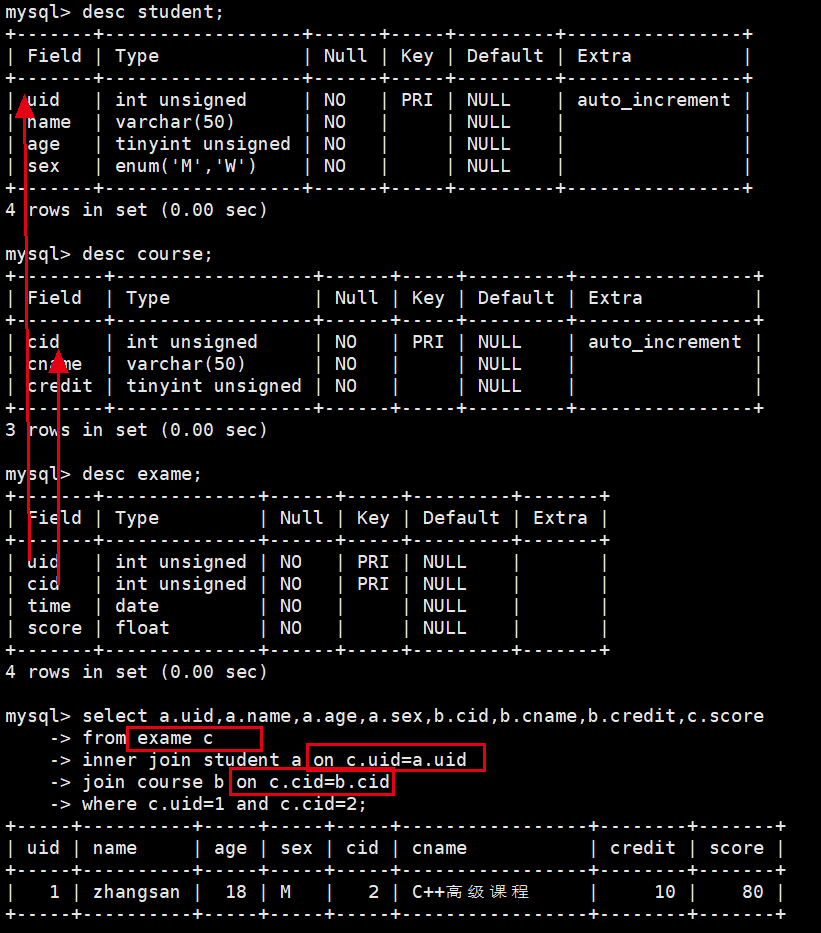
#三张表的联合查询
select a.uid,a.name,a.age,a.sex,b.cid,b.cname,b.credit,c.score
from exame c
inner join student a on c.uid=a.uid
join course b on c.cid=b.cid
where c.uid=1 and c.cid=2;
- 先考虑表和表之间用什么字段关联,即先把表的连接写好,再写where过滤条件
练习
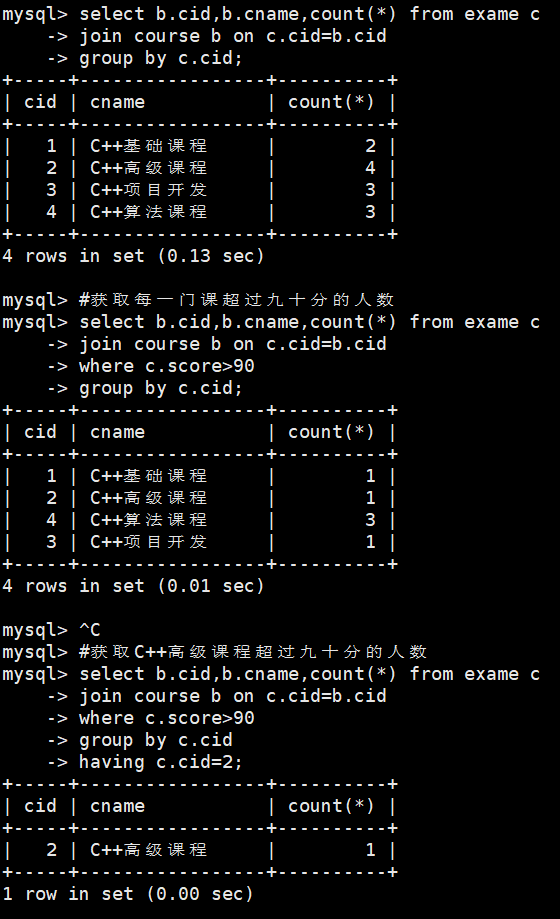
#获取每一门课考试人数
select b.cid,b.cname,count(*) from exame c
join course b on c.cid=b.cid
group by c.cid;
#获取每一门课超过九十分的人数
select b.cid,b.cname,count(*) from exame c
join course b on c.cid=b.cid
where c.score>90
group by c.cid;
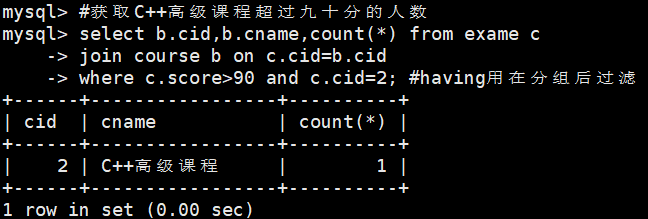
#获取C++高级课程超过九十分的人数
select b.cid,b.cname,count(*) from exame c
join course b on c.cid=b.cid
where c.score>90
group by c.cid
having c.cid=2; #having用在分组后过滤
#获取C++高级课程超过九十分的人数
select b.cid,b.cname,count(*) from exame c
join course b on c.cid=b.cid
where c.score>90 and c.cid=2;
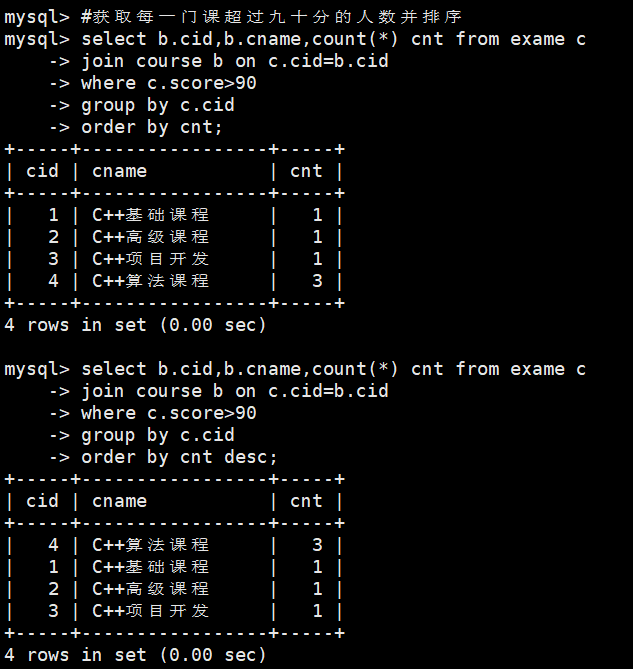
#获取每一门课超过九十分的人数并排序
select b.cid,b.cname,count(*) cnt from exame c
join course b on c.cid=b.cid
where c.score>90
group by c.cid
order by cnt;
select b.cid,b.cname,count(*) cnt from exame c
join course b on c.cid=b.cid
where c.score>90
group by c.cid
order by cnt desc;
#1、cid=2这门课程考试成绩的最高分的学生信息和课程信息
select a.uid,a.name,b.cid,b.cname,b.credit,c.cid,c.score from exame c join student a on c.uid = a.uid join course b on c.cid = b.cid where c.cid=2 order by c.score desc limit 1;
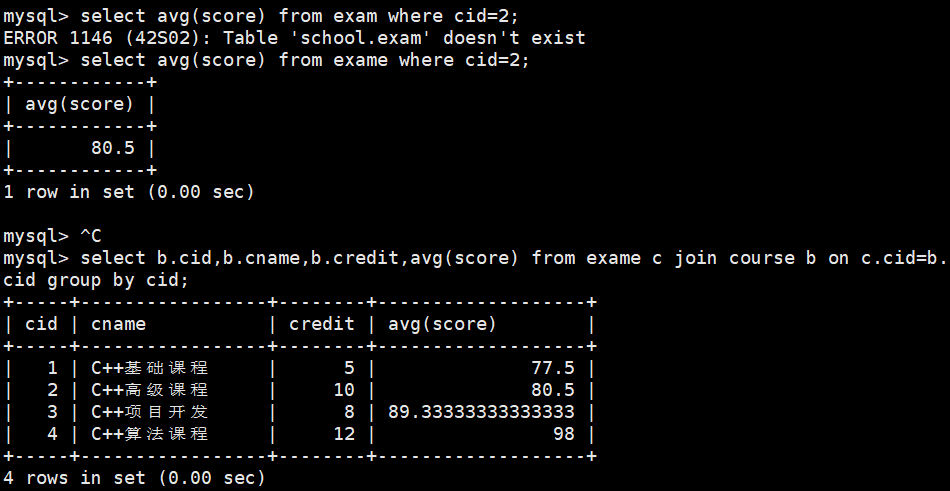
#2、cid=2这门课程的考试平均成绩&每门课程考试的平均成绩+课程信息
select avg(score) from exame where cid=2;
select b.cid,b.cname,b.credit,avg(score) from exame c
join course b on c.cid=b.cid
group by cid;
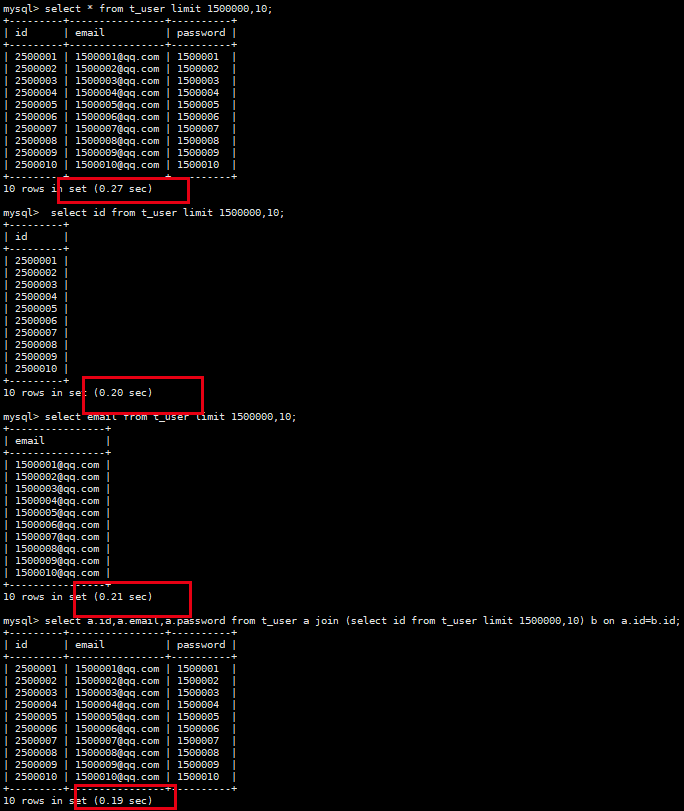
与limit相结合
select后字段的多少也会影响想查询效率
select * from t_user limit 1500000,10;
select id from t_user limit 1500000,10;
select email from t_user limit 1500000,10;
对于偏移量我们之前是使用where 优化的
select * from t_user where id>2500000 limit 10
但是有些情况我们不知道具体偏移量是多少,又想获取多列信息,那么该如何优化
select a.id,a.email,a.password from t_user a join (select id from t_user limit 1500000,10) b on a.id=b.id;
- 原因在于小表是整表扫描获取id后存入到临时表,然后再去大表搜索,

大小表
#查看两个表内连接后两个表的所有信息
explain select a.*,b.* from student a join exame b on a.uid=b.uid;
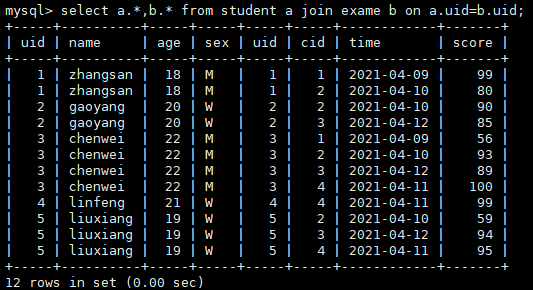
- 先执行where过滤,b就只剩3条数据,此时在进行内连接b就变成了小表,所以进行全表扫描
条件过滤
select a.*,b.* from student a join exame b on a.uid=b.uid where b.cid=3;
select a.*,b.* from student a join exame b on a.uid=b.uid and b.cid=3;
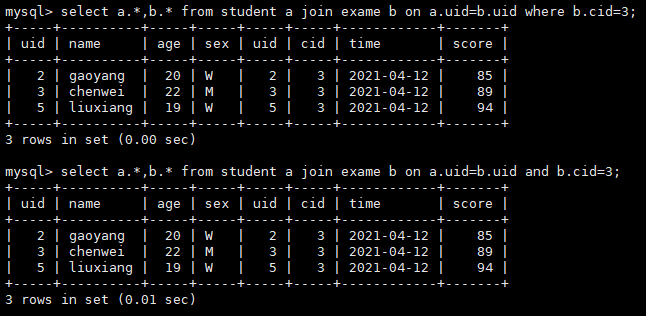
对于inner join内连接,过滤条件写在where的后面和on连接条件里面,效果是一样的
where 可以使用索引过滤,效率上比较快
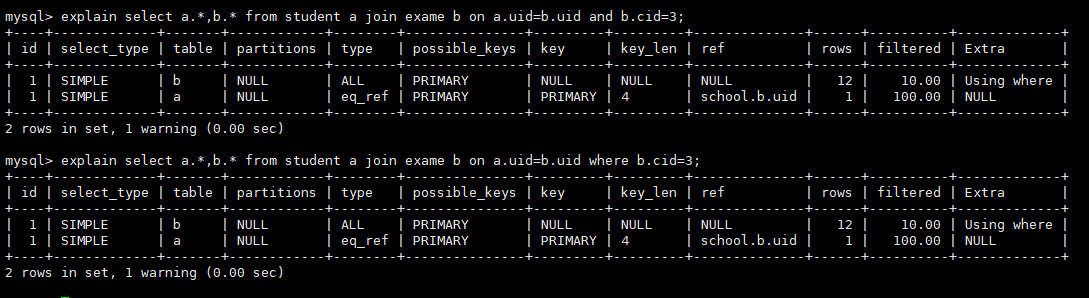
外连接
左外连接查询
// 把left这边的表所有的数据显示出来,在右表中不存在相应数据,则显示NULL
select a.* from User a left outer join Orderlist b on a.uid=b.uid where a.orderid is null;
- outer 可以省略,加了left或right就左连接或右连接
右外连接查询
// 把right这边的表所有的数据显示出来,在左表中不存在相应数据,则显示NULL
select a.* from User a right outer join Orderlist b on a.uid=b.uid where b.orderid is null;
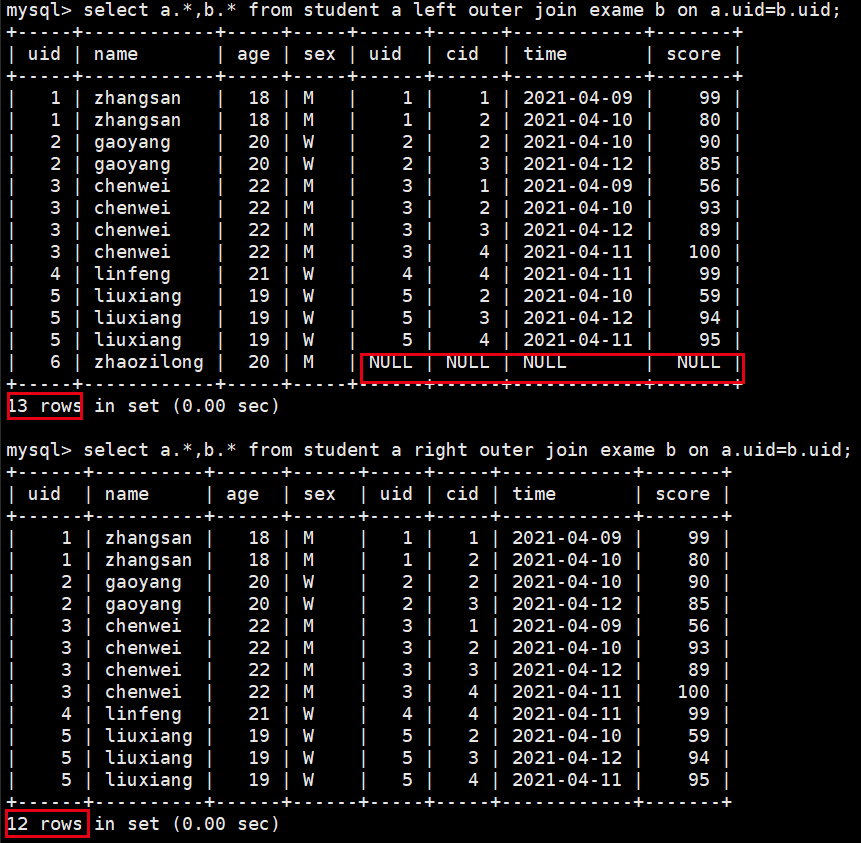
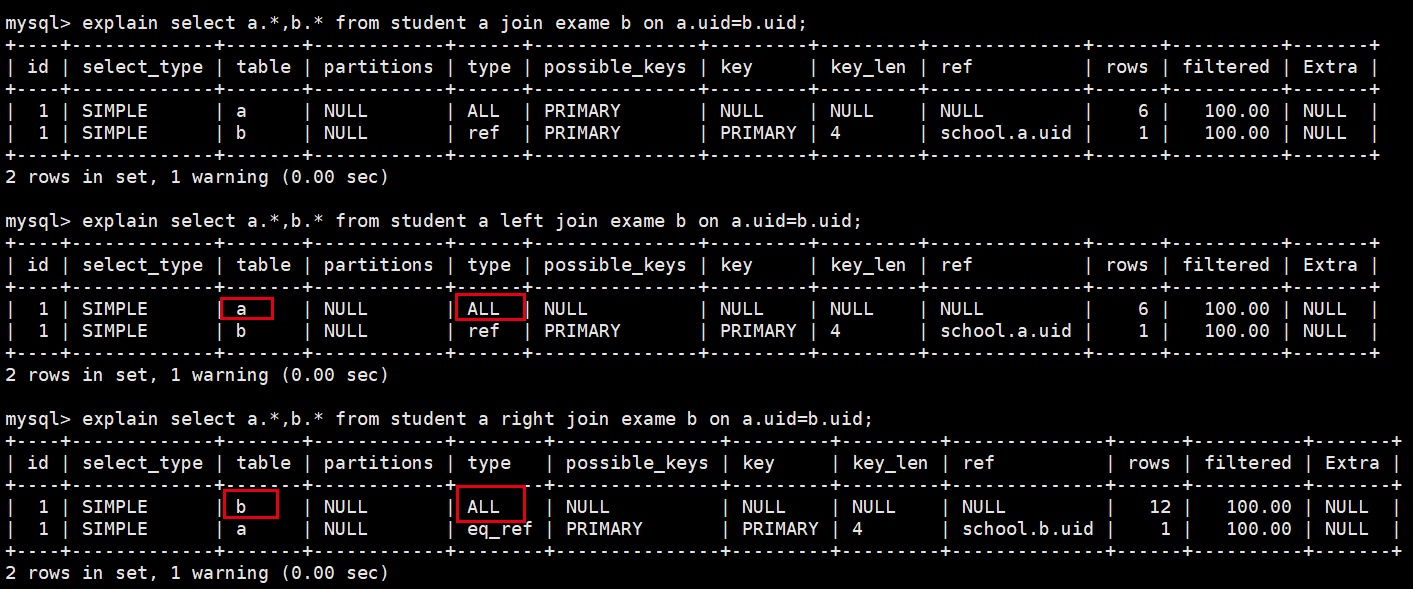
- 内连接小表全扫描
- 左连接表边表全扫描,右边匹配左边,没有为NULL
- 右连接右边表全扫描,左边匹配右边,没有为NULL
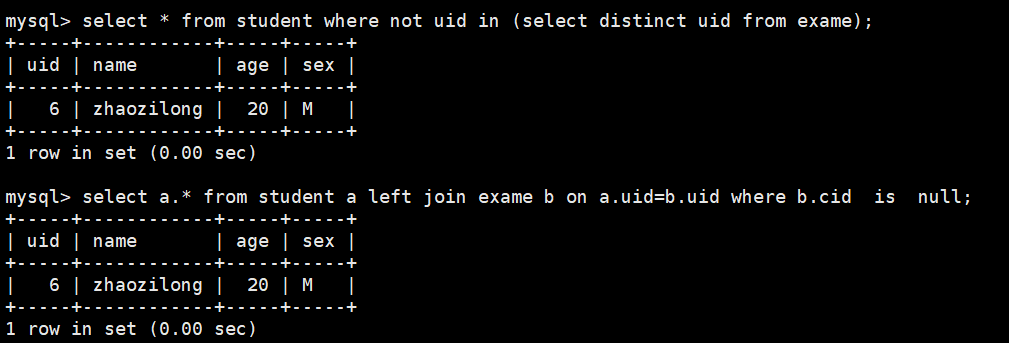
# 查询所有没有考试的同学信息
select * from student where not uid in (select distinct uid from exame);
select a.* from student a left join exame b on a.uid=b.uid where b.cid not is null;
select distinct uid from exame会产生一张中间表存储结果供外面的sql查询- 中间表也不一定都会产生,因为mysql server都会做优化,可以用explain 查看是否产生中间表
not in- in虽然会用到索引但是一般也会产生中间表,这也是为什么不喜欢用带in子查询的原因所在
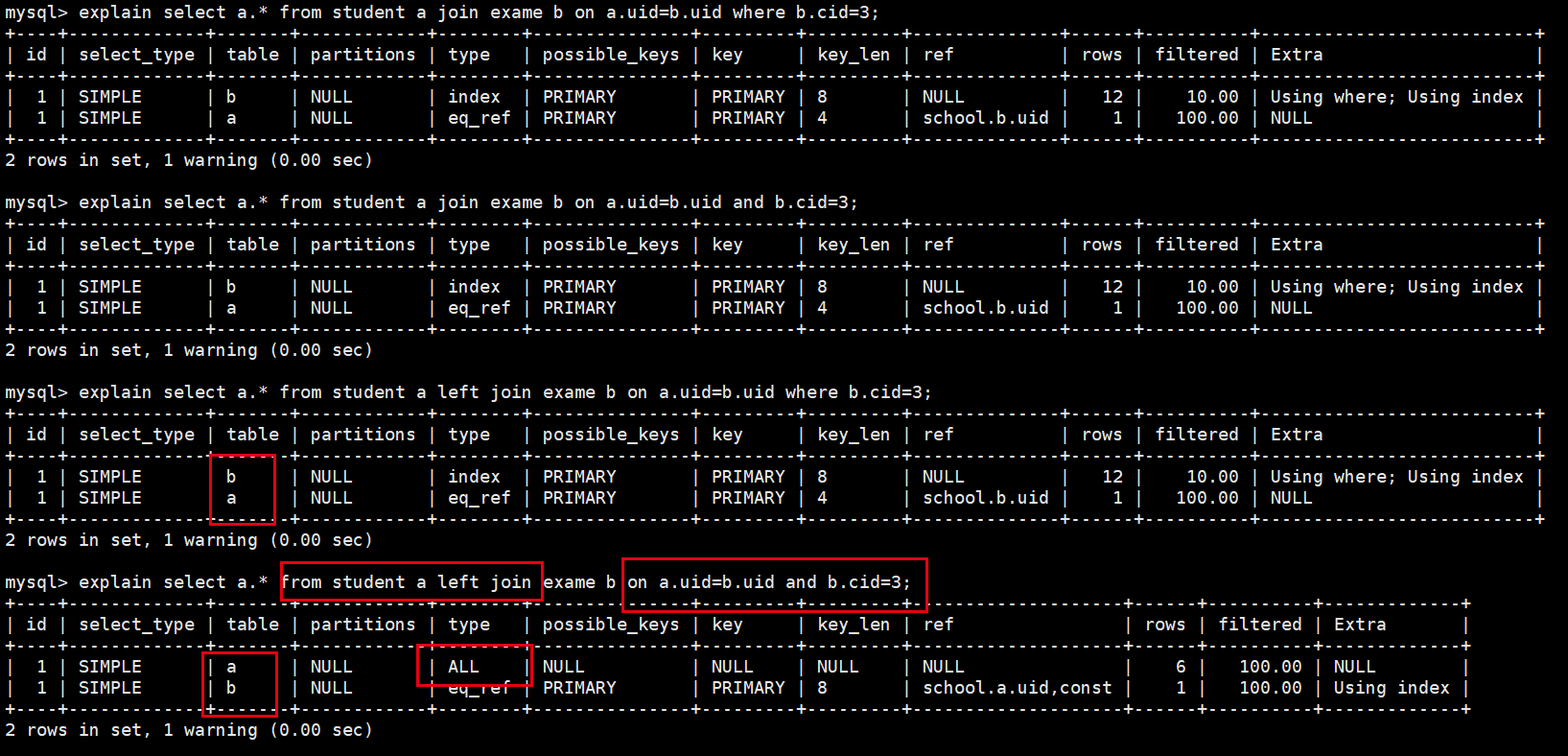
- 外连接如果on后面只写连接条件,过滤条件全写在where后,外连接就会和内连接查询结果一样
- 对于查询不在的情况,where后面值判断是否为null,其他