前言
前言
为什么叫c语言
详细请看wd_C语言
其实是因为先有高级语言ALGOL 60,简称 A 语言,后来经过简化,变为 BCPL 语言,简称 B 语言,而 C 语言是在 B 语言的基础之上发展而来的,所以就称为 C 语言。所以世界上第一个 C 语言的编译器是用 B语言编写的。
UNIX和c语言的发展史
1965年为了解决大型机连接终端数量不够用的问题(当时大型主机至多能提供 30 台终端(30 个键盘、显示器),连接一台电脑),贝尔实验室 加入了 麻省理工学院 以及 通用电气 合作的计划
1969 年前后这个项目进度缓慢,资金短缺,贝尔实验室退出了研究
1969 年从这个项目中退出的 Ken Thompson 当时在实验室无聊时,为了让一台空闲的电脑上能够运行 “星际旅行(Space Travel)” 游行,在 8 月份左右趁着其妻子探亲的时间,用了 1 个月的时间,使用汇编写出了 Unix 操作系统的原型
1970 年,美国贝尔实验室的 Ken Thompson ,以 BCPL 语言为基础,设计出很简单且很接近硬件的 B 语言(取 BCPL 的首字母),并且他用 B 语言 写了第一个 UNIX 操作系统
1971 年,同样酷爱 “星际旅行(Space Travel)” 的 Dennis M.Ritchie 为了能早点儿玩上游戏,加入了 Thompson 的开发项目,合作开发 UNIX,他的主要工作是改造 B语言,因为 B 语言 的跨平台性较差
1972 年, Dennis M.Ritchie(丹尼斯·里奇) 在 B 语言 的基础上最终设计出了一种新的语言,他取了 CPL 的第二个字母作为这种语言的名字,这就是 C 语言
1973 年初, C 语言的主体完成, Thompson 和 Ritchie 迫不及待地开始用它完全重写了现在大名鼎鼎的 Unix 操作系统
为什么说c语言移植性强
- 机器语言和汇编语言都不具有移植性,为 x86 开发的程序,不可能在Alpha,SPARC 和 ARM 等机器上运行
- 而 C 语言程序则可以使用在任意架构的处理器上,只要那种架构的处理器具有对应 的 C 语言编译器和库,然后将 C 源代码编译、链接成目标二进制文件之后即可运 行
为什么c语言不能叫跨平台
Java编写的任何代码,无序修改即可在任何一个平台上运行,所以称之为跨平台语言
我们所讲的 C 标准,当然可以通过不同的编译器编译后在任何一台平台上运行,但是 C 标准除了文件操作之外,是没有涉及到操作系统硬件资源的接口的,比如进程调度,网络通信等 ,这些接口均为每一个操作系统独有的,windows与 Linux 这些接口有差异,一旦你的 C 程序中使用了这些接口,代码放到另外一个平台就无法编译通过了
C语言的优势
C 语言的**执行效率**一直是高级语言中的第一!另外 Java 及其他脚本语言中没有指针,无法访问物理地址,所以系统中的驱动都需要用 C或 C++进行编写。
学习c语言的目标
- 理解运行的逻辑
- 内存变化
- 程序的调试能力
vs studio 调试方法
打断点->F5·(启动程序)->打开监视、调用堆栈、输出、内存窗口
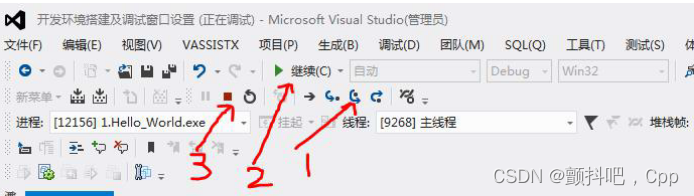
按钮 1 是单步执行按钮F10,点击该按钮一次,程序会向下执行一步;按钮 2 是继续执行按钮,点击后,程序会执行到最后,或者执行到下一个断点,按钮3 是停止执行按钮shift F5,点击后程序直接停止运行。(左键点击断点就可以取消断点)
在断点调试状态下,我们点击菜单栏的调试,选择窗口,然后依次点击监视,调用堆栈,内存,三个调试窗口,调用堆栈,监视,内存窗口对于后面我们调试程序及理解程序执行原理都至关重要,这次调出以后,后面每次调试程序都会自动弹出
程序调试方法:
- 断点单步调试
- 判断打印调试
- 等等
内存地址及内存空间
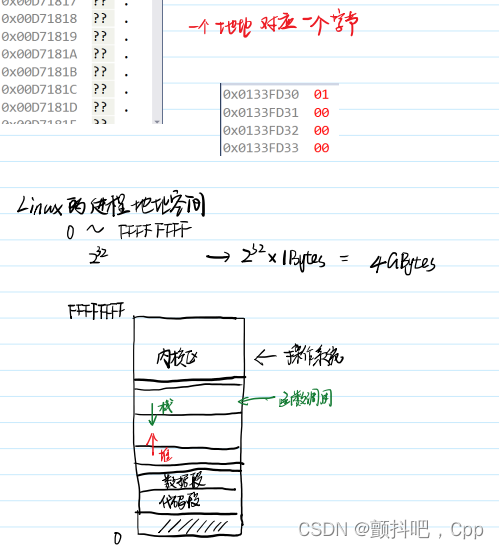
i 的值是 0x00000001,为什么显示效果为 01 00 00 00 呢,这个是因为英特尔的 CPU 为小端存储,所以低位在前,高位在后
内存地址只是一个编号,代表一个内存空间(!容易产生误区)
内存地址只是一个编号,代表一个内存空间,这个空间大小不会随编号的位数改变而改变(变成2个字节,4个字节),一个内存地址所代表的永远是1个字节。内存的每一个字节都有一个编号,16位操作系统、32位操作系统只是改变这个编号的长短,不会影响内存的最小单元大小,仅仅是个编号。唯一影响的是所能表示的个数(寻址能力)。
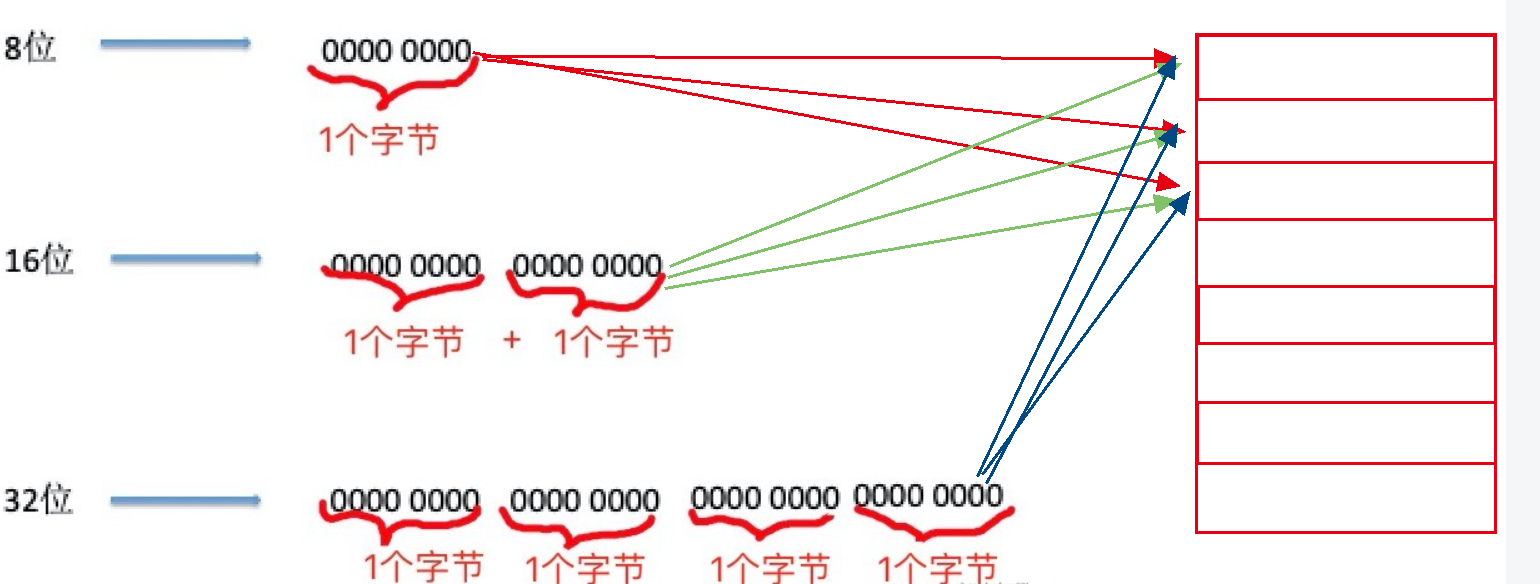
所以这个16位的cpu,所有表示的地址个数是2^20 = 1048576个,一个地址所指大小1个字节 ,也就是1M;32位的cpu,所有表示的地址个数是2^32 = 4294967296个,一个地址所指大小1个字节 ,也就是4G;

显示代码行号
工具 --> 选项 -->勾选行号
程序生成过程
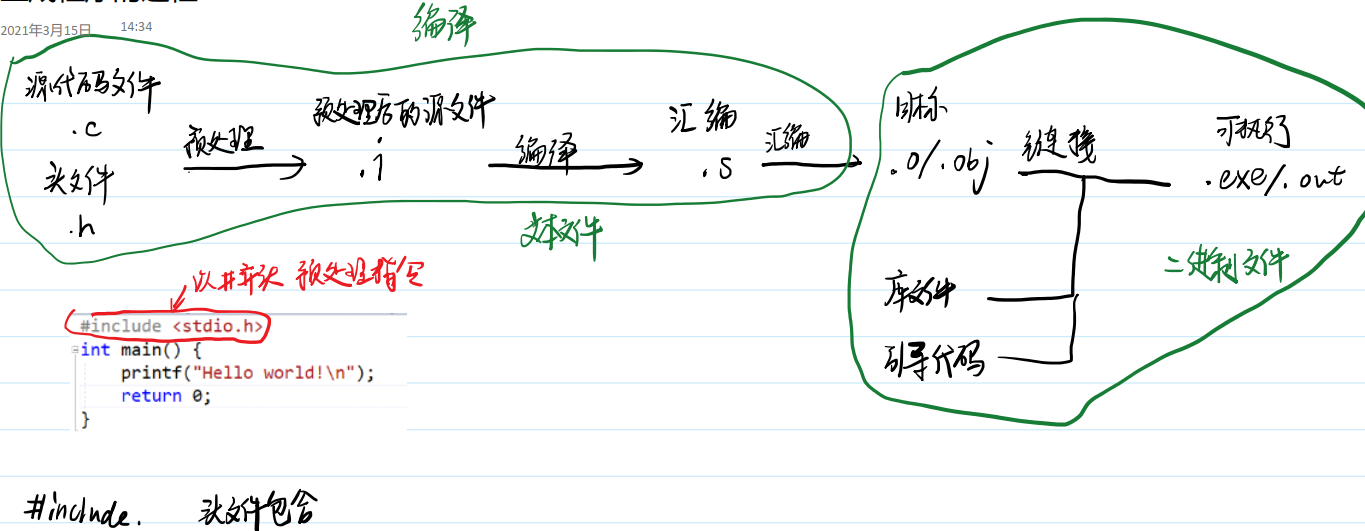
首先我们编写源代码f.c 经过编译后,我们会得到 f.obj 文件,f.obj 文件中均为0101 类型的机器码,也就是 cpu 能够识别的微指令(英特尔的机器指令)去运行,f.obj 文件并不能执行,因为我们调用的标准库函数的代码并不在 f.obj 文件中,例如上面 main.c 的printf 函数,printf 函数的代码并不在 main.obj 中,这时经过链接,就得到可执行文件 f.exe,了解这个编译过程,对于我们后面编写程序遇到编译错误后,分析编译错误,我们可以区分清楚是编译错误,还是链接错误。
预编译指令
#include 头文件包含
#define 宏定义
右侧项目代码->属性->配置属性->c/c+±>预编译器->预处理到文件(是)
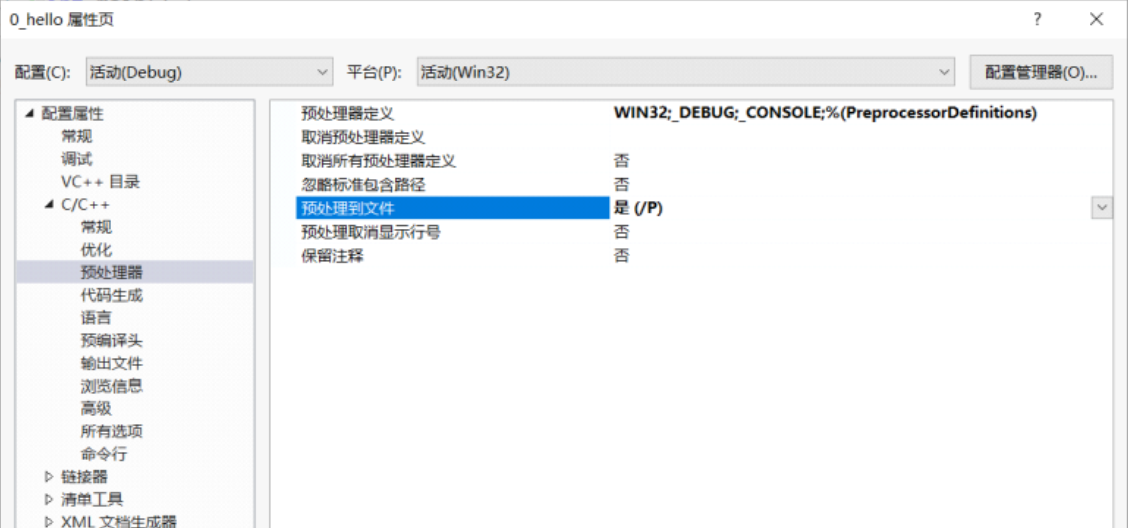
预处理c和C++源文件并将预处理的输出写到文件,此选项取消编译,因此不会生成.obj文件
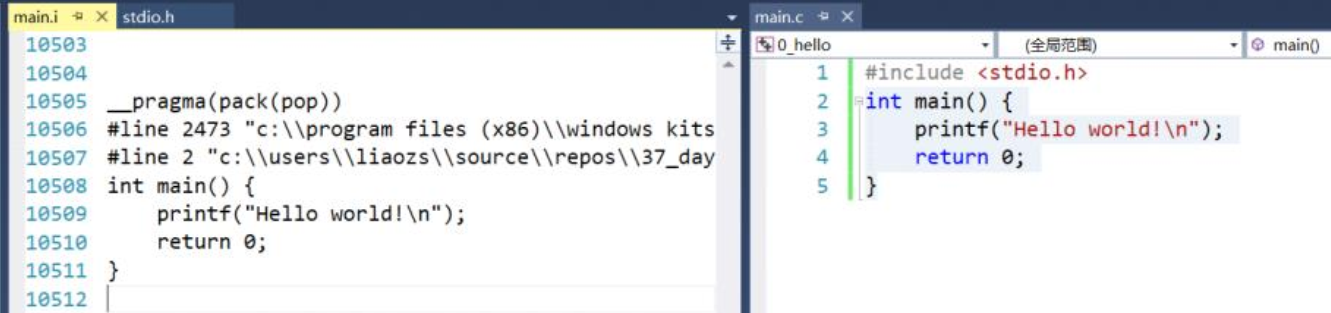
#include<>和#include""的区别
#include<>:编译器直接从系统类库目录里查找头文件
比如在VS2013中,编译器会直接在<Visual studio 2013安装目录>\VC\include目录下查找到stdio.h这个文件,这就是编译器的类库目录;
在Linux GCC编译环境下,一般为/user/include和/usr/local/include。
例如,我们自定义一个头文件"test.h",把它放在项目工程文件所在目录,然后用“#include <>”的形式加载头文件test.h,编译时会直接报错:No such file or directory.
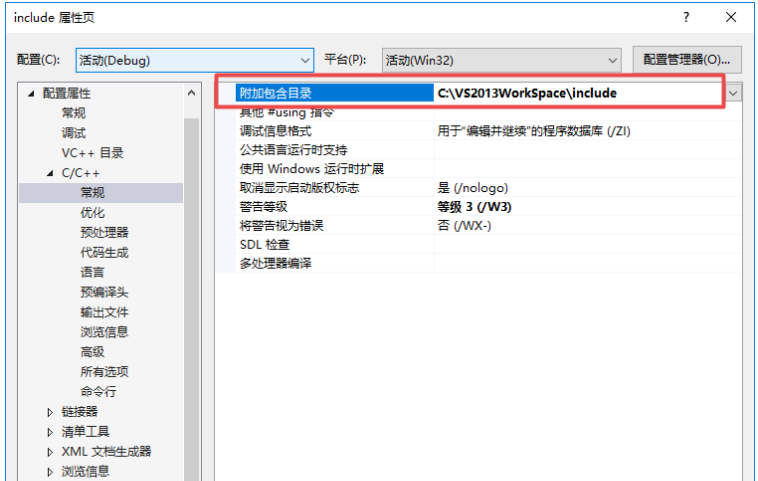
#include"":默认从项目当前目录查找头文件,如果在项目当前目录下查找失败,再从项目配置的头文件引用目录查找头文件
所谓项目配置的引用目录,就是我们在项目工程中设置的头文件引用目录,Windows VS编译环境如下图所示。在Linux GCC编译环境下,则一般通过在Makefile文件中使用参数指定引用目录。
虽然#include""的查找范围更广,但是这并不意味着,不论是系统头文件,还是自定义头文件,一律用#include""包含。