编译器角度理解c++代码的编译和链接
编译器角度理解c++代码的编译和链接
c/c++这种本地编译型语言的编译过程
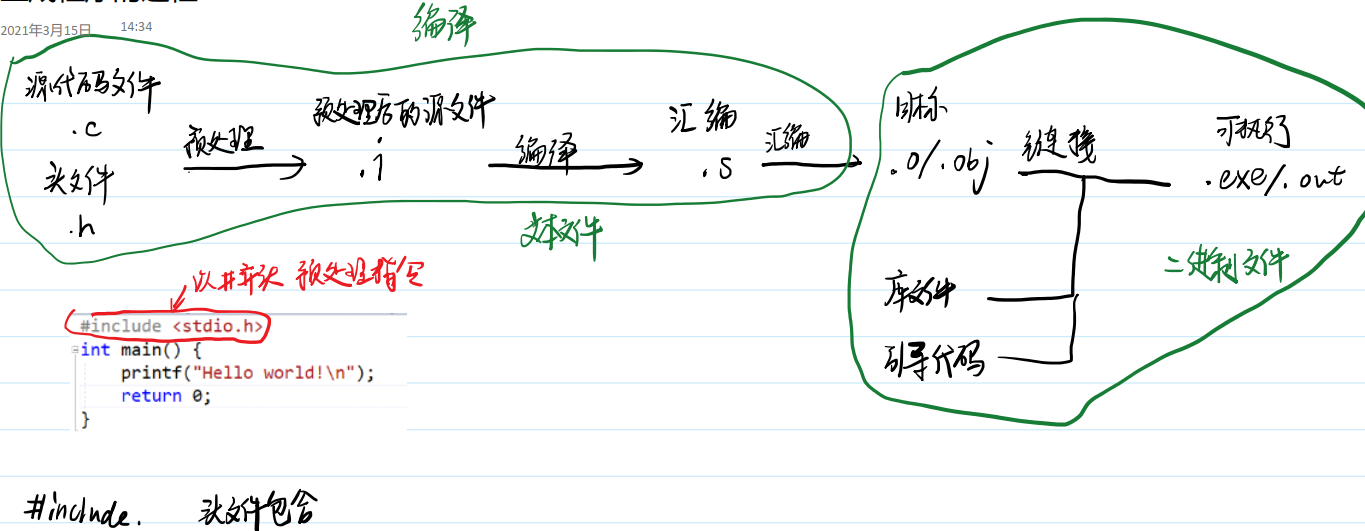
重点:
*.o文件的组成格式是什么样的?- 可执行文件的组成格式是什么样的?
- 链接的两个步骤做的是什么事情?
- 符号表中的符号怎么理解?
- 符号何时分配虚拟地址?
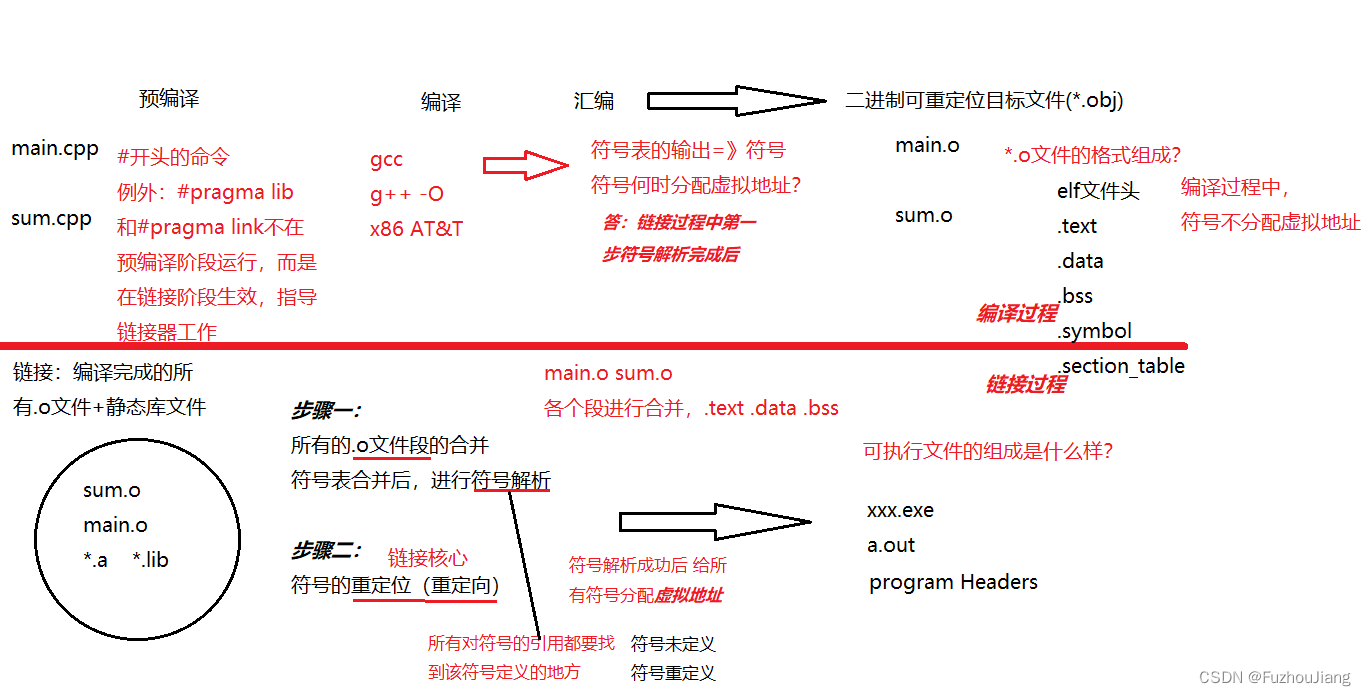
#pragma lib表示程序执行时需要连接的库,所以必须在链接阶段生效- 假如有个函数start,想让程序执行的时候从start开始执行而不是main,需要
#pragma link修改程序的入口地址,所以也必须持续到链接阶段。 - (
#include、#define、#ifdef、#ifndef、#endif等) - 编译阶段可以gcc,也可以g++,
g++ -O 0 1 2 3 ...表示优化级别 - 编译完成后会生成相应平台的汇编代码,汇编阶段有两种架构的汇编代码
x86和AT&T- 在gdb下使用
set disassembly-flavor intel转换为intel格式的汇编 set disassembly-flavor att转换为att格式的汇编
- 在gdb下使用
- 汇编就是把汇编代码转成特定平台的二进制码
链接主要工作🍔
⭐在编译过程中,源文件经过预编译、编译和汇编的过程,生成了二进制的可重定位的目标文件;
⭐此后,在链接过程,所有.o文件对应的段进行合并,其中,符号表进行合并后,需要对符号进行解析
- ⭐对符号进行解析:所有对符号的引用,都要找到其定义的地方
⭐对符号进行解析完成后,就会给所有的符号分配虚拟地址;
- ⭐符号重定位:就是将给符号分配后的地址写回代码段;
示例
根据如下两段代码分析
其中注释表示符号和存放在进程虚拟地址空间的位置
//main.cpp
// 引用sum.cpp里定义得全局变量及函数
extern int gdata; // gdata *UND*
int sum(int, int); // _Z3sumii *UND*
int data = 20; // data .data
int main() // main .text
{
int a = gdata;
int b = data;
int ret = sum(a, b);
return 0;
}
// sum.cpp
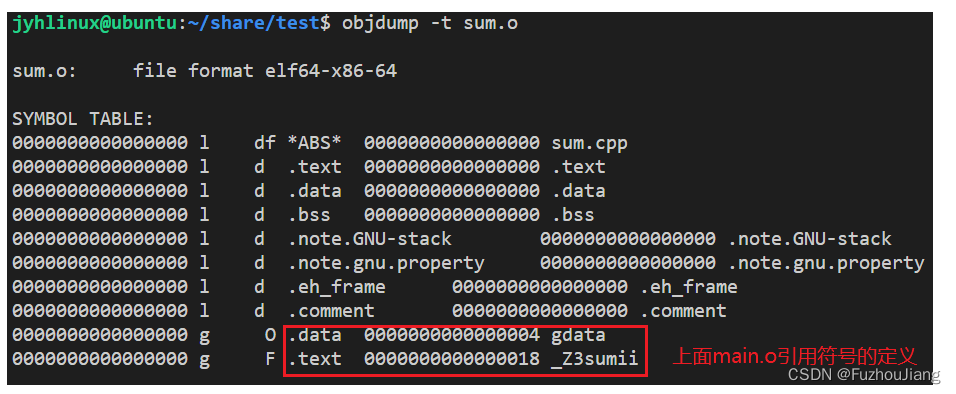
int gdata = 20; // gdata .data
int sum(int a, int b) // _Z3sumii .text
{
return a + b;
}
编译阶段:
g++ -c main.cpp #编译成main.o
g++ -c sum.cpp #编译成sum.o
查看符号表:
objdump -t main.o #不仅显示符号表,还显示了段的信息
nm main.o #简洁,符号表(符号名称、类型和地址等基本信息)
readelf -s main.o #也可以查看符号表信息
查看main.o符号表
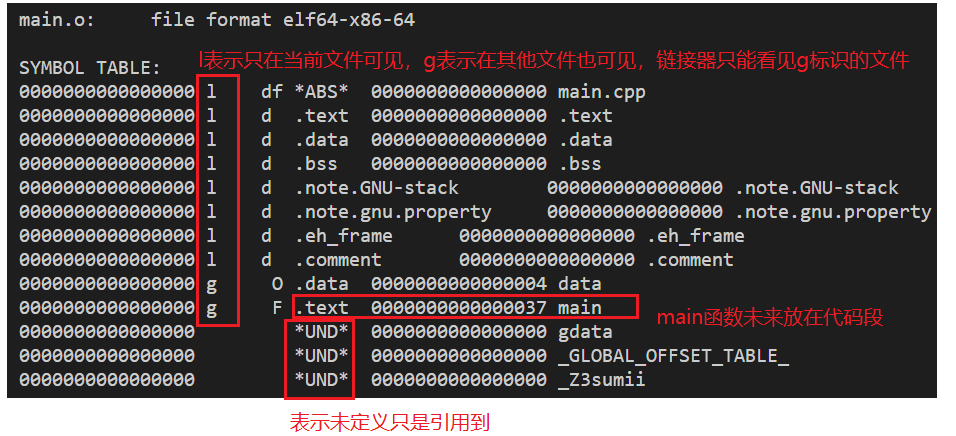
- l = local
- g = global
- 符号表都为0,
- 因为引用的符号都不知道在哪里定义的,肯定无法分配虚拟地址
- 符号的虚拟地址是在链接时分配的
查看sum.o符号表
分析main.o文件头
汇编器把汇编代码转成可重定向的文件时不仅生成了符号表,还生成了各种各样的段
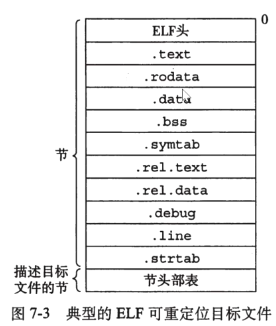
*.o文件的组成,需要关注的:
ELF文件头
.text
.data
.bss
.symbal (符号段)
.section table(段表/节头部表)
readelf -h main.o #查看文件头 (elf头)
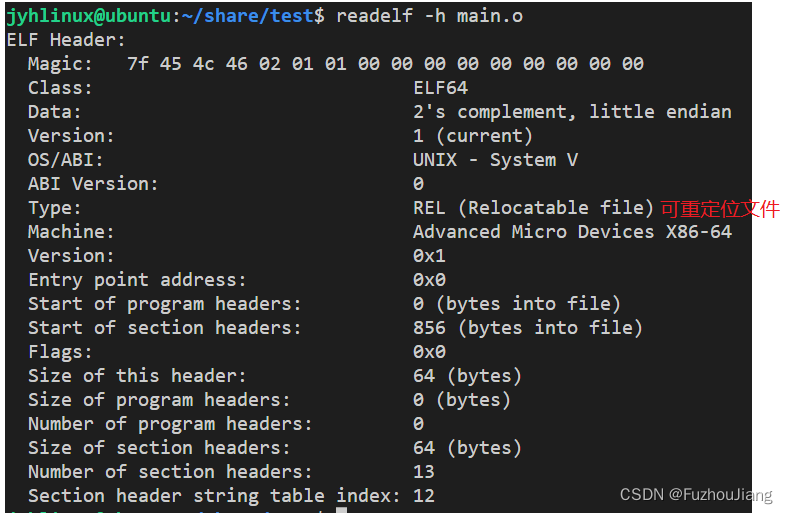
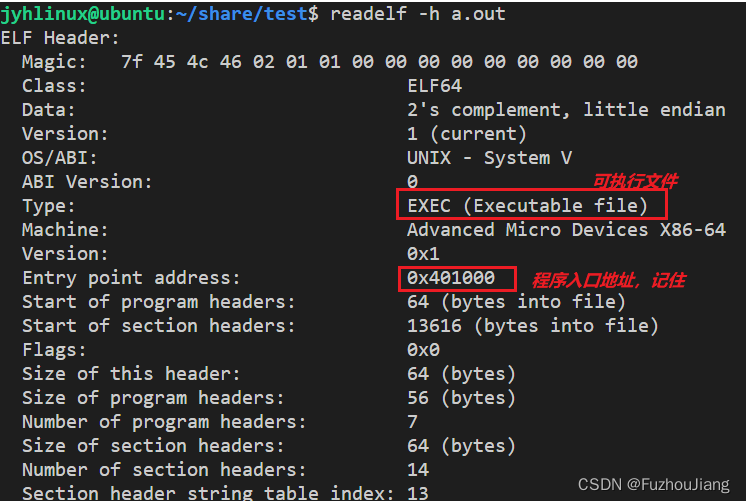
- 这是 可重定义的文件 不是 可执行文件,所以入口地址
Enter point address = 0x0, 0x0不可以访问
打印目标文件各个段:
readelf -S main.o #查看有哪些段以及各个段的信息
readelf -s main.o #查看符号表信息
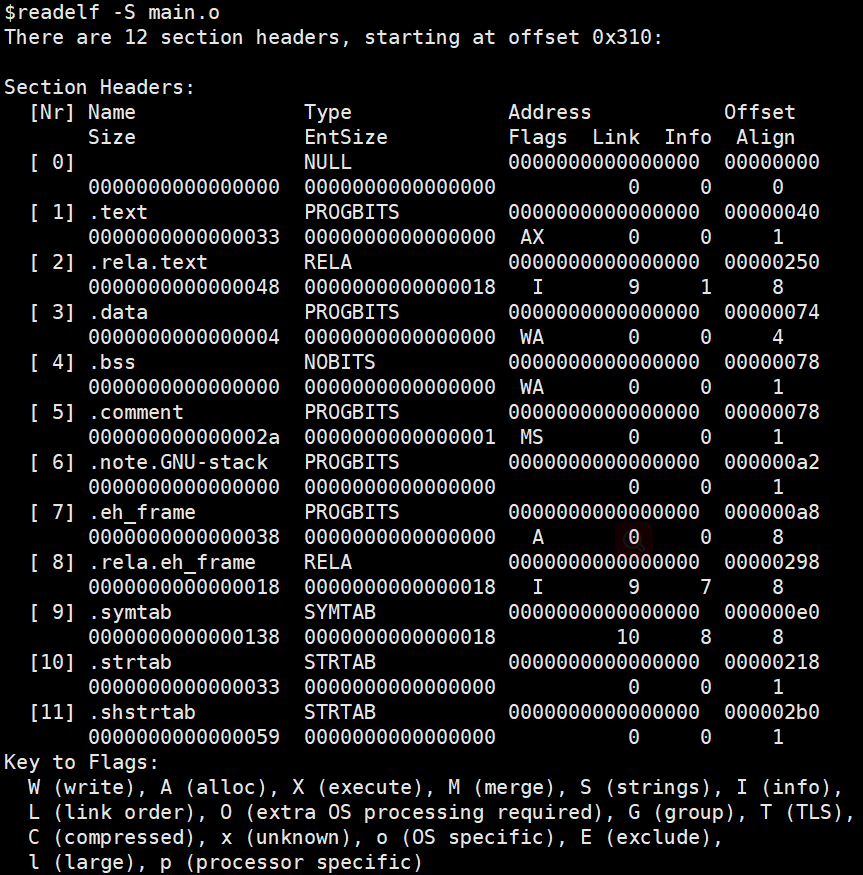
- flag标志
- A 分配空间的
- W 可写的
- X 可执行的
分析main.o的.text段
$ g++ -c main.cpp -g
$ objdump -S main.o
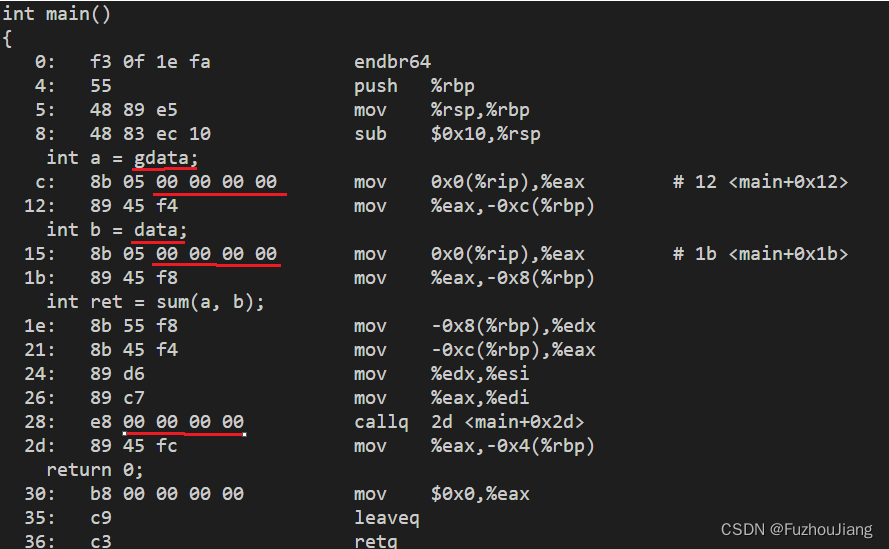
由上图可知编译过程中,
链接阶段
链接的过程🍔🍔🍔
所有
.o文件段的合并,符号表合并后,进行符号解析main.o和sum.o中各个段进行合并- .text <=>.text, .data<=>.data, .bss<=>.bss ...
- 符号表属于文件段之一(.symbal)
符号表合并后,进行符号解析
- 符号解析:所有对符号的引用,都要找到该符号定义的地方
- 在符号表中找对应的符号是否只出现于
.text或.data段- 若一次都无,则符号未定义(报错);
- 若出现多次,符号重定义(报错)
链接时就是在符号表中找对应的符号是否只出现于
.text或.data段;若一次都无,则符号未定义(报错);若出现多次,符号重定义(报错)
- (链接的核心),给所有符号分配虚拟地址,前面都是全0
- 符号重定向:符号解析成功后,给所有的符号分配了虚拟地址,前面符号的指令值都是全0,所以需要把符号的具体地址写到符号的指令上
符号什么时候分配虚拟地址:链接过程,第一步符号解析完成后
手动链接:ld -e main *.o
-e参数用于指定链接后生成的可执行文件的入口点(entry point)ld -e main *.o意味着将所有的*.o目标文件链接在一起,并指定main函数作为程序的入口点
可执行文件
查看可执行文件a.out的符号表
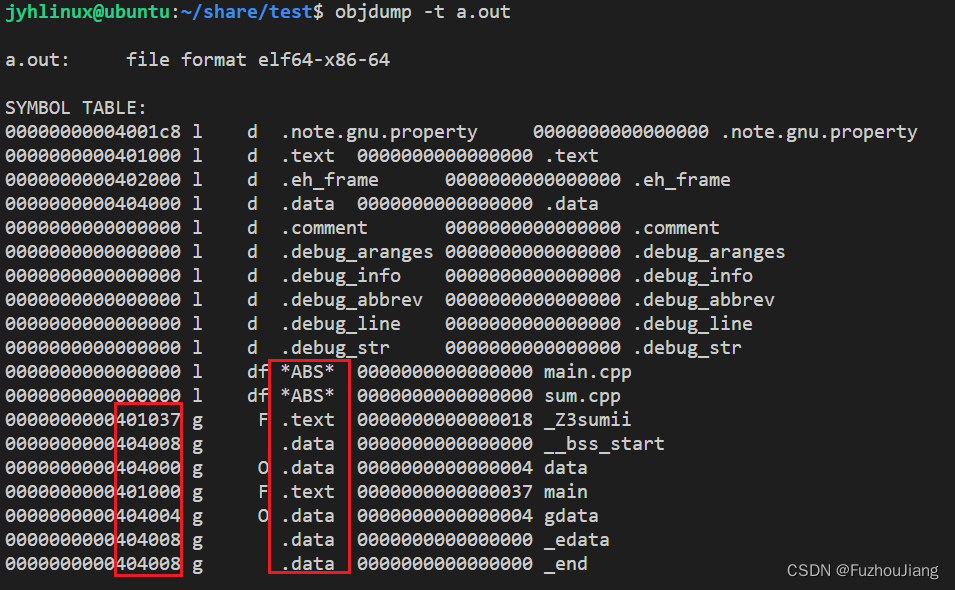
- 可以看出每个符号都有其对应的虚拟地址以及所在的区域,运行时就可以将其加载到指定段中(如.data .text)
分析可执行文件的elf头
再看一下a.out的汇编代码
objdump -S查看汇编
g++ -g -c main main.cc #前提编译时 加-g
objdump -M intel -S main.o #反汇编、与相关联的源代码交替并且以英特尔的框架显示🍗🍗🍗
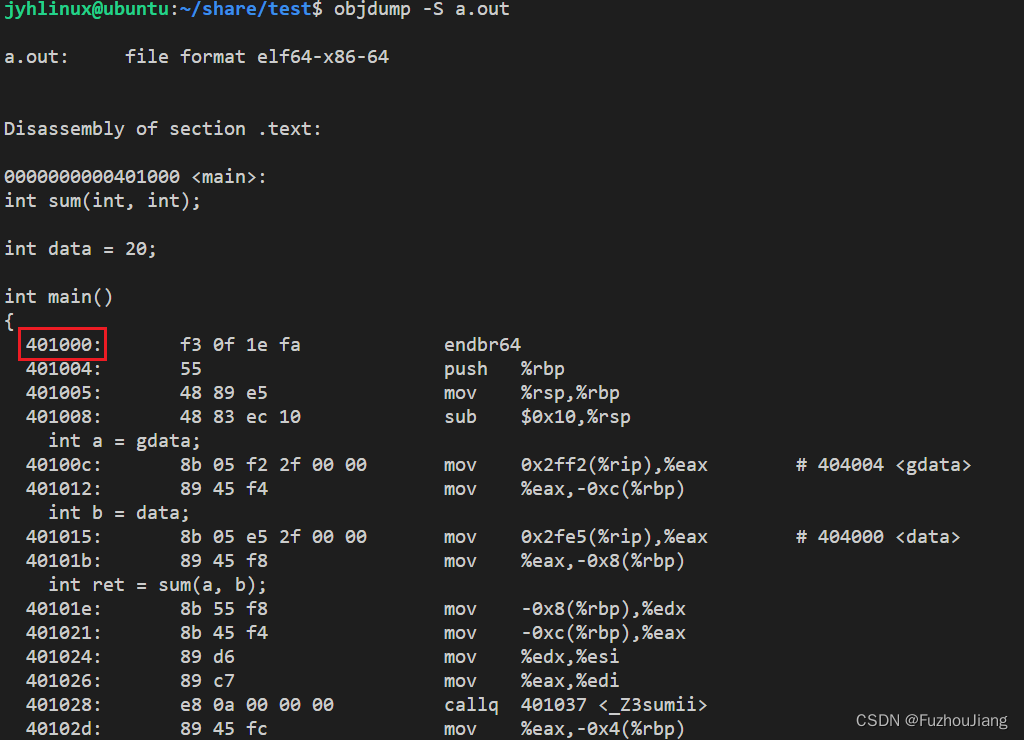
- 可以发现
main函数内第一条指令地址就是前面的入口地址(entry)
gdb查看汇编
使用 disassemble 命令,或者简写为 disas
在
gdb提示符下,设置断点或让程序运行到你想要查看汇编代码的位置break main b main在gdb下使用
set disassembly-flavor intel转换为intel格式的汇编使用
run命令运行程序一旦程序停止在断点或你指定的位置,可以使用
disassemble命令查看汇编代码。如果你没有指定任何参数,gdb会显示当前函数的汇编代码
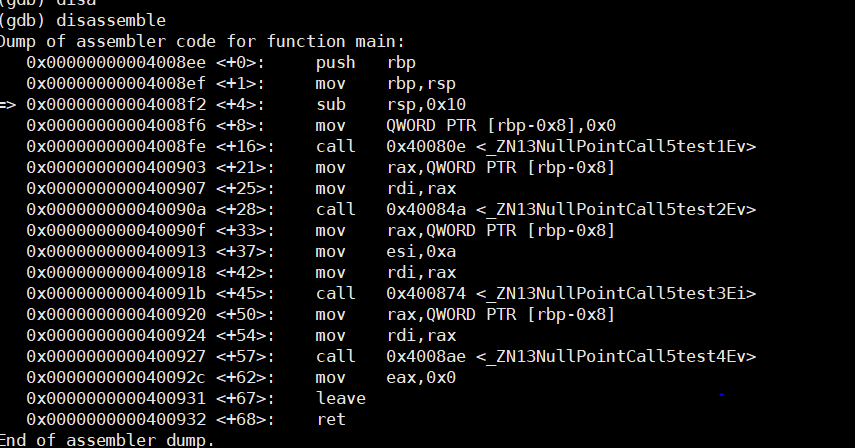
如果你想要查看特定函数或地址的汇编代码,你可以将函数名或地址作为参数传递给
disassemble命令。例如:disas main disas 0x00000000004008ee如果你想在每一步执行时都看到对应的汇编指令,你可以使用
layout asm命令。这将打开一个新的窗口,显示当前执行点的汇编代码。然后,你可以使用stepi或nexti命令逐步执行汇编指令,并查看每步的汇编代码变化。退出
q或quit
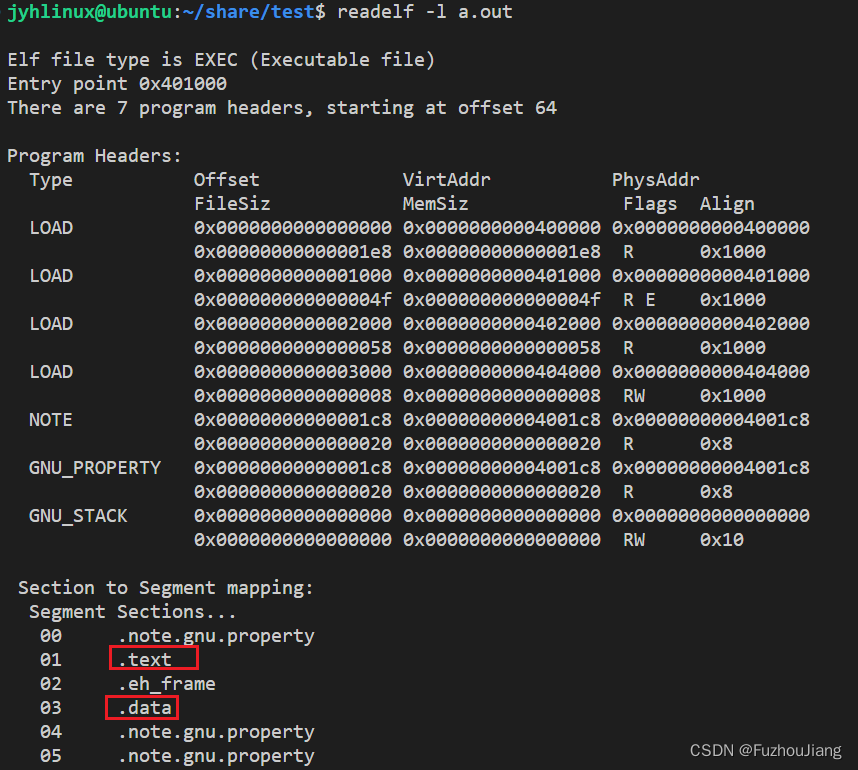
查看可执行程序的program headers段
readelf -l a.out #从查看可执行程序的program headers
a.out 比*.o多了program headers段,有两个load(加载段),告知系统,运行时把哪些内容加载到内存中(.text, .data)
物理内存和虚拟内存映射🍗🍗🍗
运行程序时的工作大概如下图,数据加载到指定段,将进程的虚拟地址映射到物理地址空间:
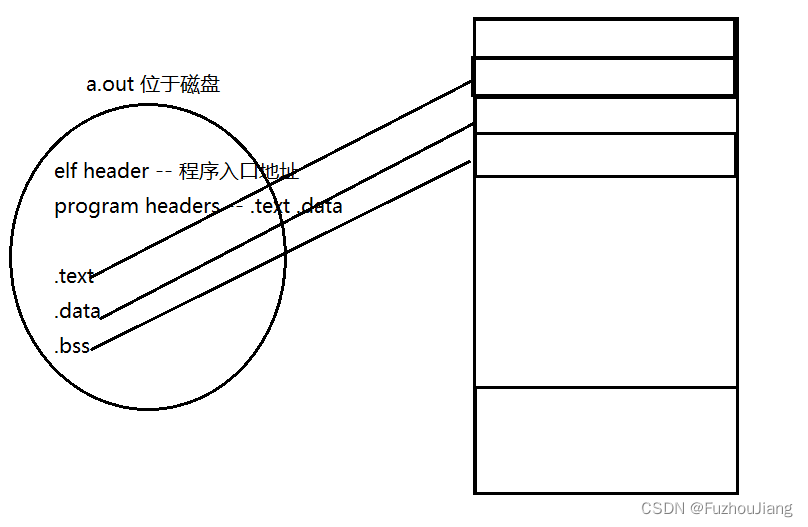
a.out位于磁盘中,a.out包含很多段
- elf header , 告诉程序入口地址在哪里
- program headers, 告诉系统加载文件中.text .data段到内存中
并没有直接加载到物理内存,而是做一个地址映射,把.text .data .bss映射到cpu虚拟地址(进程的虚拟地址空间)中
如果发现访问的地址还没有做映射,则会产生页面异常
页面异常=》执行地址映射页面异常处理程序,分配物理内存
进阶阅读
- 《CSAPP》第七章
- 《程序员的自我修养》第2、3、4、6章